Data warehouses are a critical component of modern data architecture in enterprises that leverage massive amounts of data to drive quality of their products and services. A data warehouse is an OLAP (Online Analytical Processing) database that collects data from transactional databases such as Billing, CRM, ERP, etc. and provides a layer on top specifically for fast analytics, reporting and data mining.
Cloud data warehouse integrations are a new breed that bring the added advantage of cost-effectiveness and scalability with pay-as-you-go pricing models, a serverless approach, and on-demand resources made possible by separating compute and storage.
While the benefits of moving from on-prem data warehouses to cloud might outweigh the disadvantages, there are some important challenges that companies need to be aware of. One of them being data movement—solutions like Amazon Snowball are great for initial large-scale data transfer, but the real challenge is in seamlessly moving data to the cloud data warehouses as companies continue to gather more data. Add to this the complexity of transforming and enriching data in-flight before storing it for further, advanced analytics.
The other aspect related to data movement is that data-driven enterprises are constantly discovering new data sources and enriching current ones by updating existing information at source. To enable consistency between sources and targets the industry-wide design pattern being adopted is called Change Data Capture (CDC)–where changes in data are detected based on timestamps, version numbers, etc. These changes are then made available to external systems in the form of transaction or binary logs, for example, to take action.
Similar to CDC is data drift where data structure gets altered at source or mid-stream. For example, new pieces of information are captured by adding new columns to an existing data source. Or in some cases the schema is not known and must be inferred at runtime. In a rather static environment CDC and data drift may not impact the line of business, but being able to propagate metadata changes without any downtime or intervention while data is flowing is crucial for enterprises looking to perform real-time analytics and gain competitive advantage.
Getting Started Moving to Your Cloud Data Warehouse
In this article, you’ll learn how to use newly released StreamSets Snowflake Enterprise Library* to accelerate your journey to the Snowflake cloud data warehouse.
Here are the installation instructions:
- Download, install, and run Data Collector
- In Data Collector, click on the Package Manager icon.
- On the sidebar menu on the left, click on Enterprise Stage Libraries, select Snowflake Enterprise Library from the list, click Install icon. Once the installation completes, follow instructions to restart Data Collector.
*Note: Snowflake Enterprise Library is not available under the Apache 2.0 Open Source License. You may use it solely for internal, non-commercial use. If you would like to use this library in a production setting, you may enter into a separate commercial license. Please contact us for more information.
Unlock Insights From Apache Web Server Logs
In particular, we’ll look at an example scenario that addresses Data Drift–where new information is added mid-stream and when that occurs the new table structure and new column values are created in Snowflake automatically.
To illustrate, let’s take HTTP web server logs generated by Apache web server (for example) as our main source of data. Here’s what a typical log line looks like:
150.47.54.136 - - [14/Jun/2014:10:30:19 -0400] "GET /department/outdoors/category/kids'%20golf%20clubs/product/Polar%20Loop%20Activity%20Tracker HTTP/1.1" 200 1026 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36"
As you can imagine, there’s a wealth of information which can be extracted to potentially provide better services, products, and/or improve user experiences. Some of the attributes in the log entries include client IP, HTTP method (GET, POST, etc.), HTTP response code, request URL, request timestamp, client browser and platform. Although, before these attributes can be leveraged for further analysis, they must be ingested and stored in a structured format for better and faster queryability.
Pipeline Overview
Before we dive into details, here’s the dataflow pipeline overview:

For simplicity the web server logs are being loaded from local file system but they can be just easily ingested from AWS S3, Kafka, etc.
- Field Type Converter processor is used to convert attributes like HTTP response code, request timestamp, HTTP version, etc. from string to numeric values.
- Using Expression Evaluator we’re able to decode request URL in UTF-8 format so it’s human readable, and also parse product names from the request URL–which will enable us to use product names in SQL where clauses to perform joins and apply aggregate functions in Snowflake.
- For Snowflake destination, we’ll need provide account credentials, warehouse, database, schema, and table name. (Note: if the table doesn’t exist in Snowflake, it will be created automatically.)
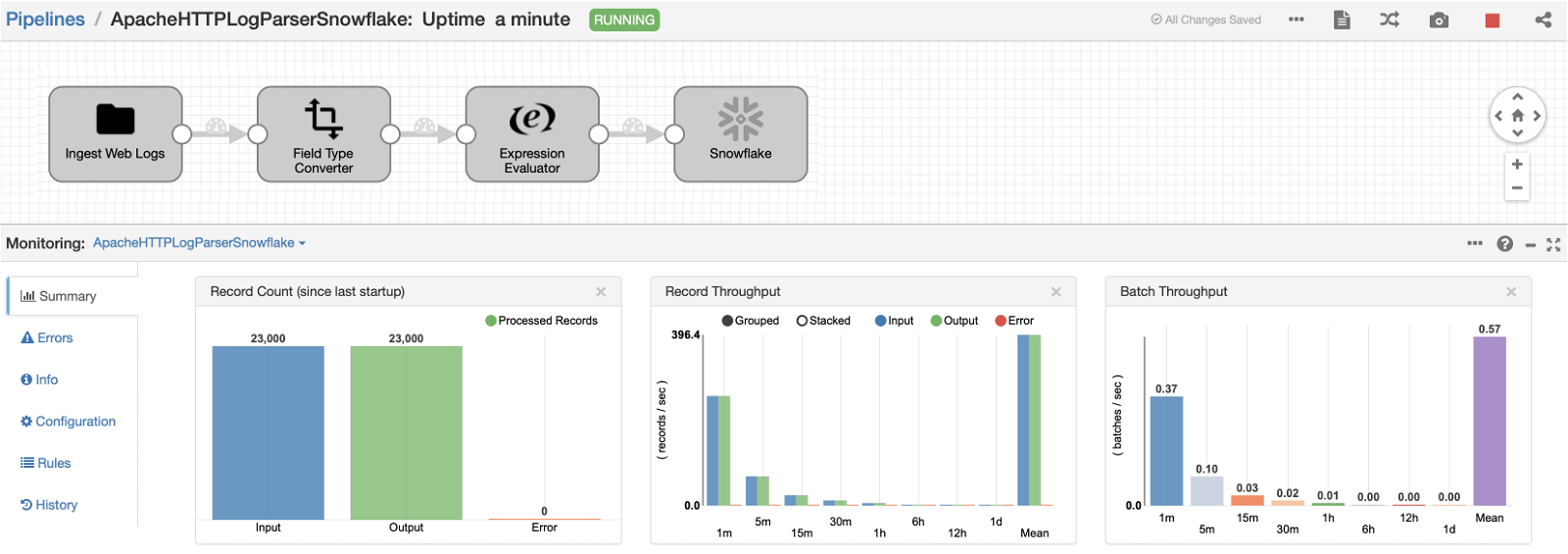
Here’s a snapshot of dataflow pipeline in execution mode
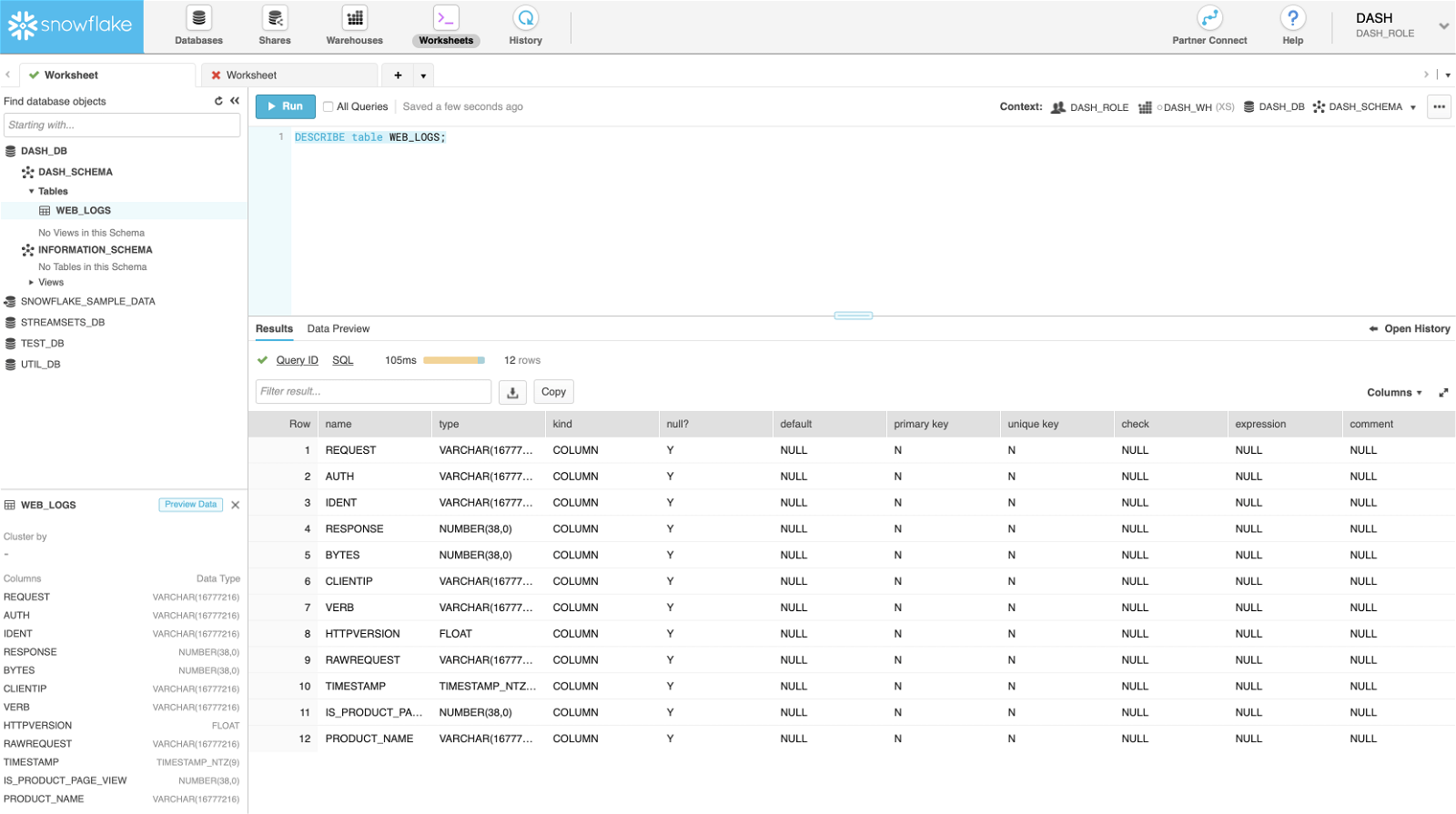
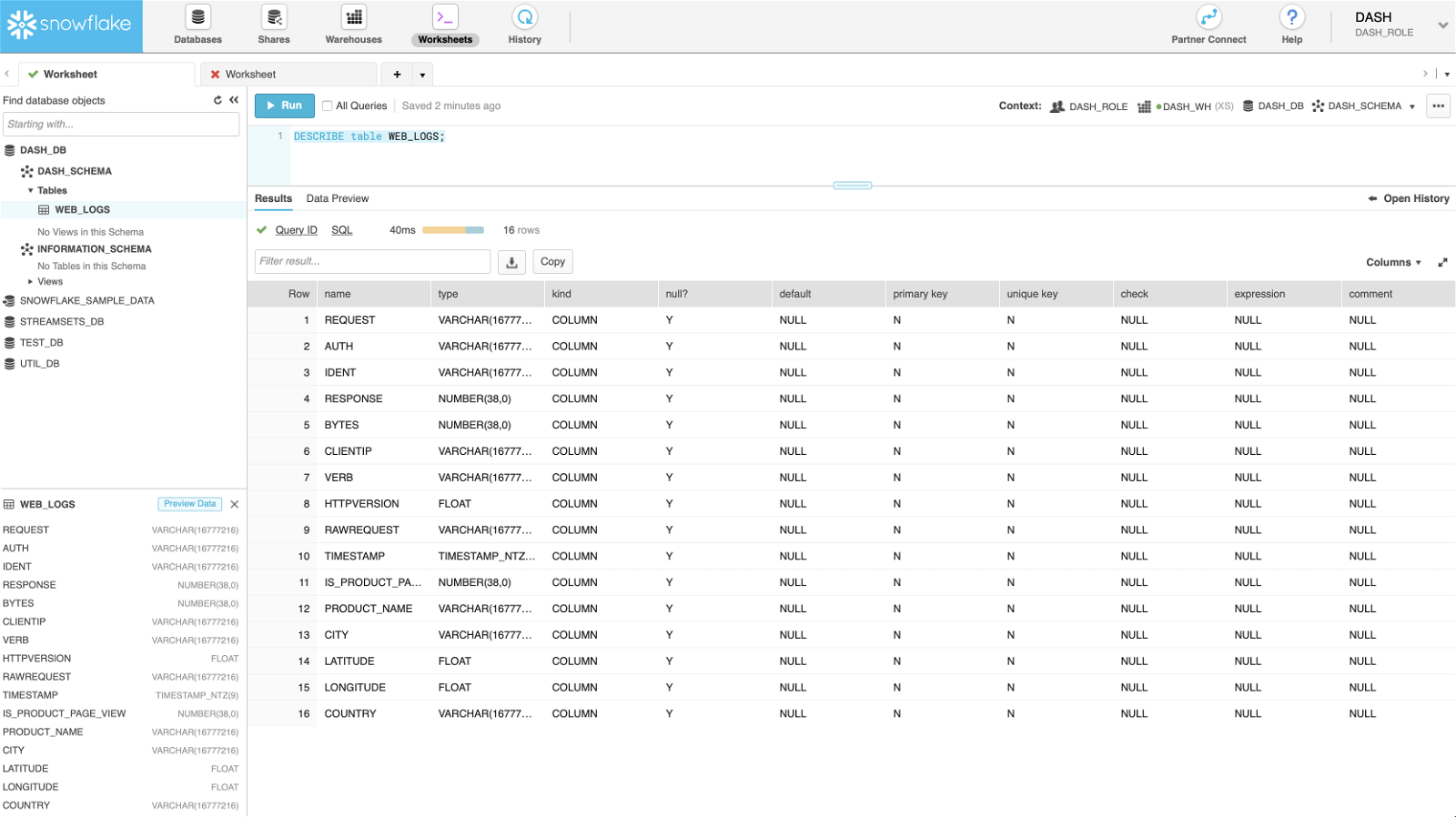
At this point, here’s what the WEB_LOGS table structure looks like in Snowflake. Note: In this case, the table WEB_LOGS didn’t exist before and was created automatically after the pipeline was started.
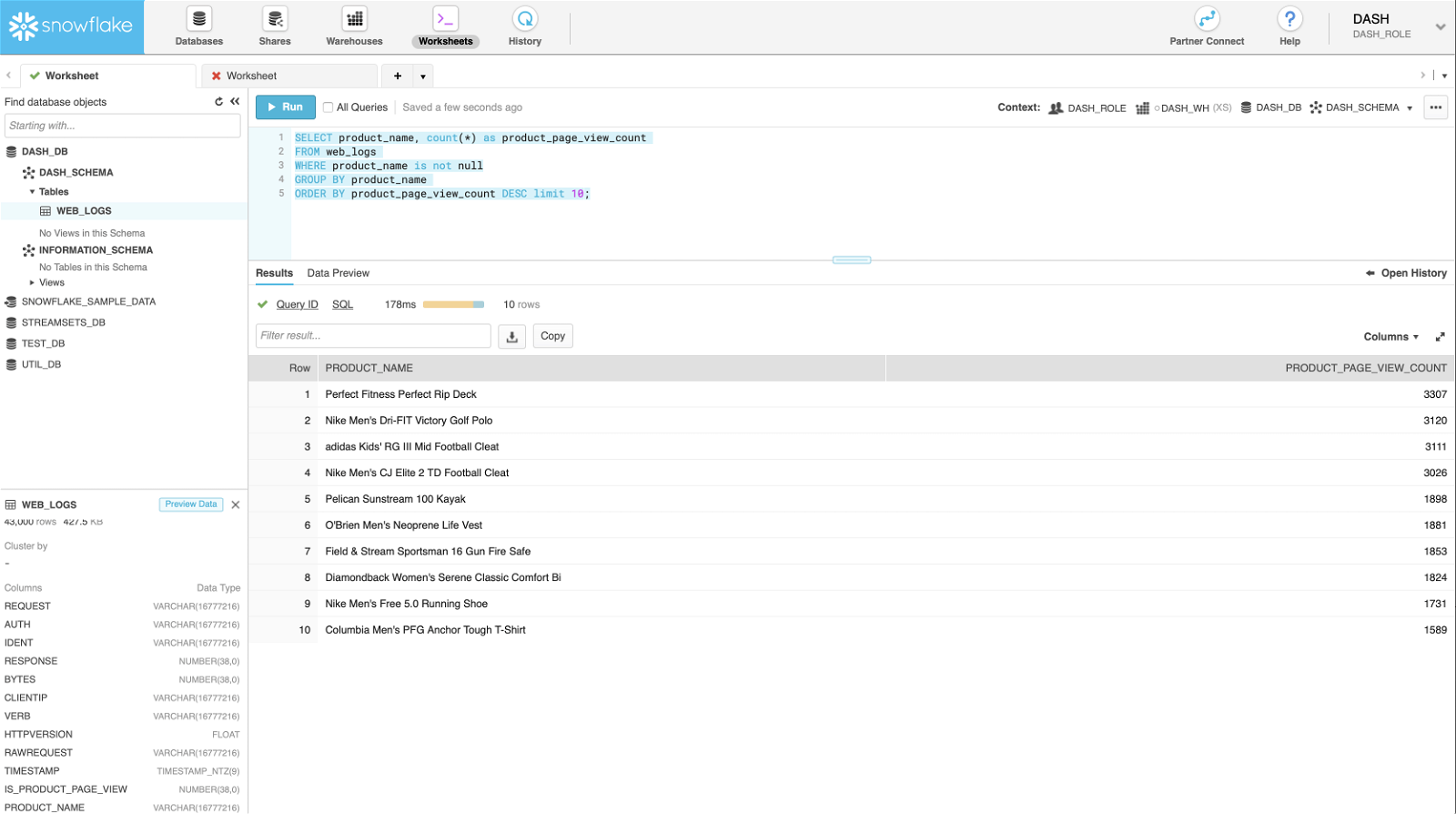
Now we’re ready to run queries in your cloud data warehouse, Snowflake.
Top 10 most viewed products
Recall that using Expression Evaluator we were able to parse product names from the request URL–that makes writing such queries pretty straightforward.
SELECT product_name, count(*) as product_page_view_count FROM web_logs WHERE product_name is not null GROUP BY product_name ORDER BY product_page_view_count DESC limit 10;
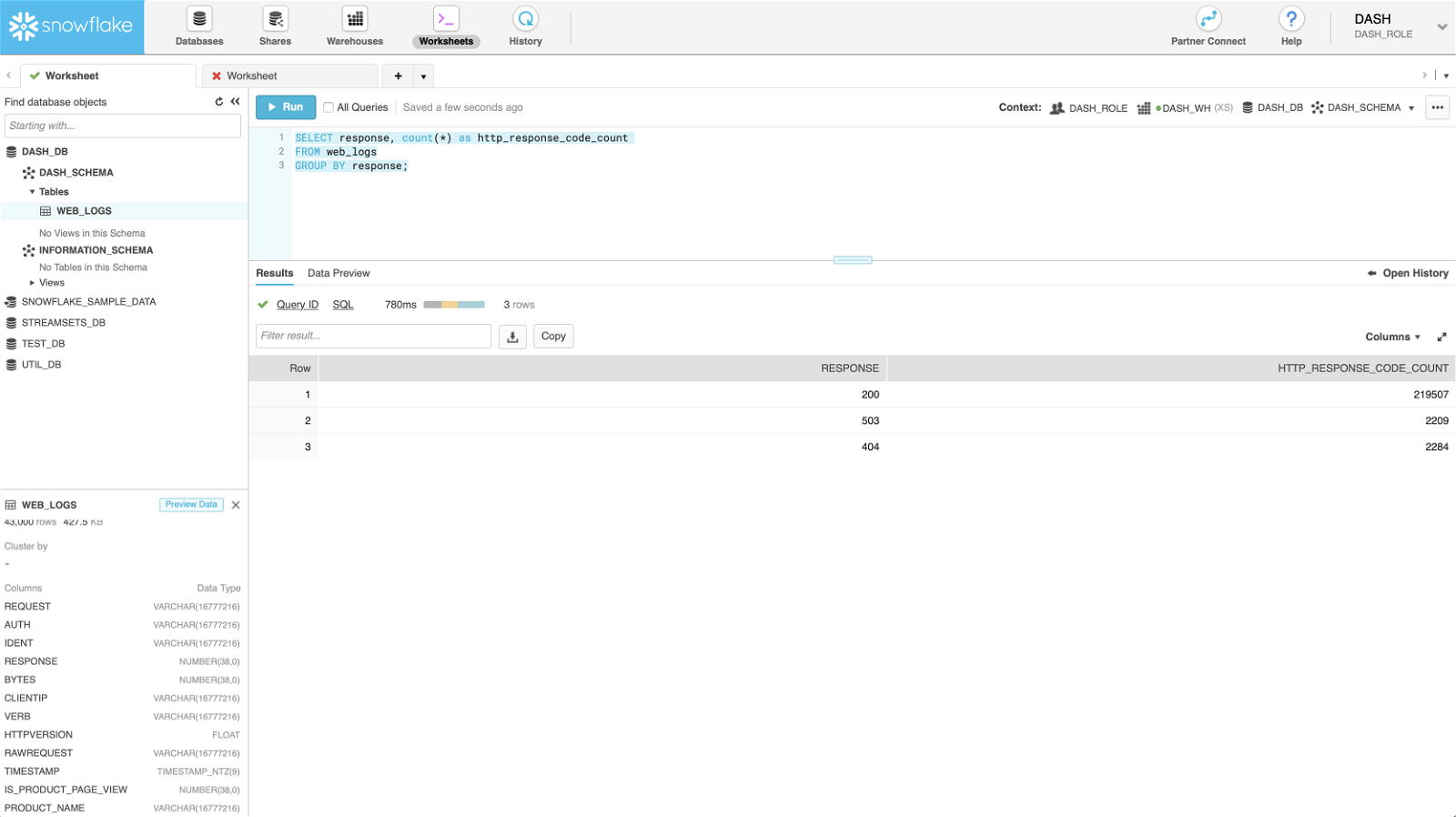
Failed (403, 500, etc.) vs. successful (200) HTTP requests
SELECT response, count(*) as http_response_code_count FROM web_logs GROUP BY response;
Correlate product page views vs revenue generated from sales
Assuming purchase orders are also being recorded in the cloud data warehouse, you could correlate product page views vs. revenue generated from sales of those products. By doing so you might find that some products are viewed a lot, but not purchased. In reality, there could be several reasons for this—for example, on the product view page where most visitors spent time, there could be a typo in the price or the button might be broken.
There is risk in looking for answers within partial data. Correlating two data sets for the same business use case shows value, and being able to do so seamlessly within the platform makes it easier for data team members and for the organization.
Similarly, you can perform other exploratory data analysis based on browser type, platform, timestamp, etc.
Data Drift And Data Enrichment in Your Cloud Data Warehouse
So far we’ve looked at how easy it is to implement dataflow pipelines in order to ingest semi-structured data and store it in Snowflake cloud data warehouse using StreamSets. In this section, we’ll enrich web server logs midstream and see the changes reflected in Snowflake automatically.
To illustrate, we’ll add Geo IP processor to the existing pipeline to lookup and add city, country, latitude, and longitude information based on the client IP address present in web server log entries.
Here’s what the updated dataflow pipeline looks like:

And here’s the updated data structure reflected automatically in Snowflake.
Now we’re ready to execute some location-based queries.
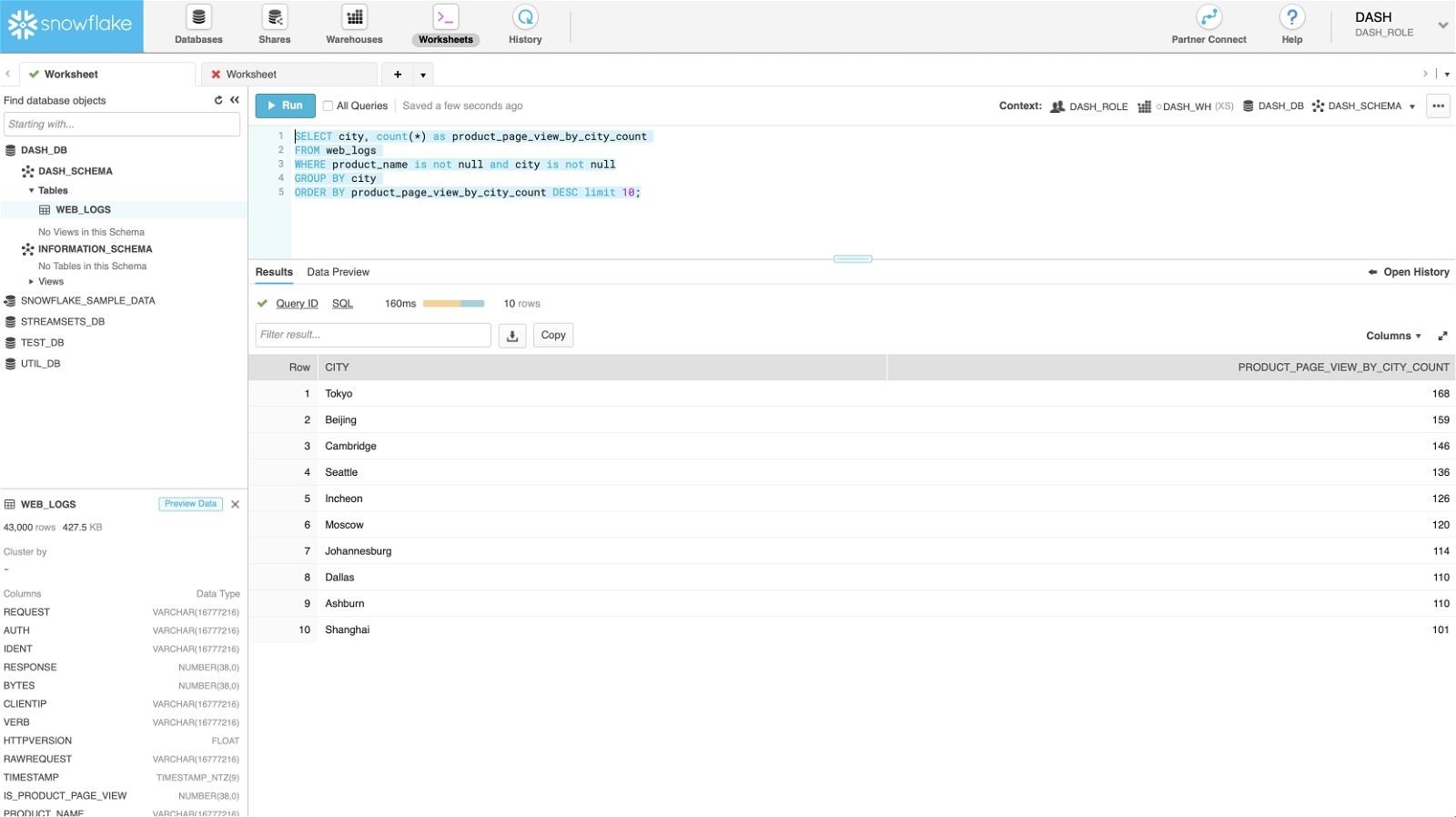
Top 10 product page views by cities
SELECT city, count(*) as product_page_view_by_city_count FROM web_logs WHERE product_name is not null and city is not null GROUP BY city ORDER BY product_page_view_by_city_count DESC limit 10;
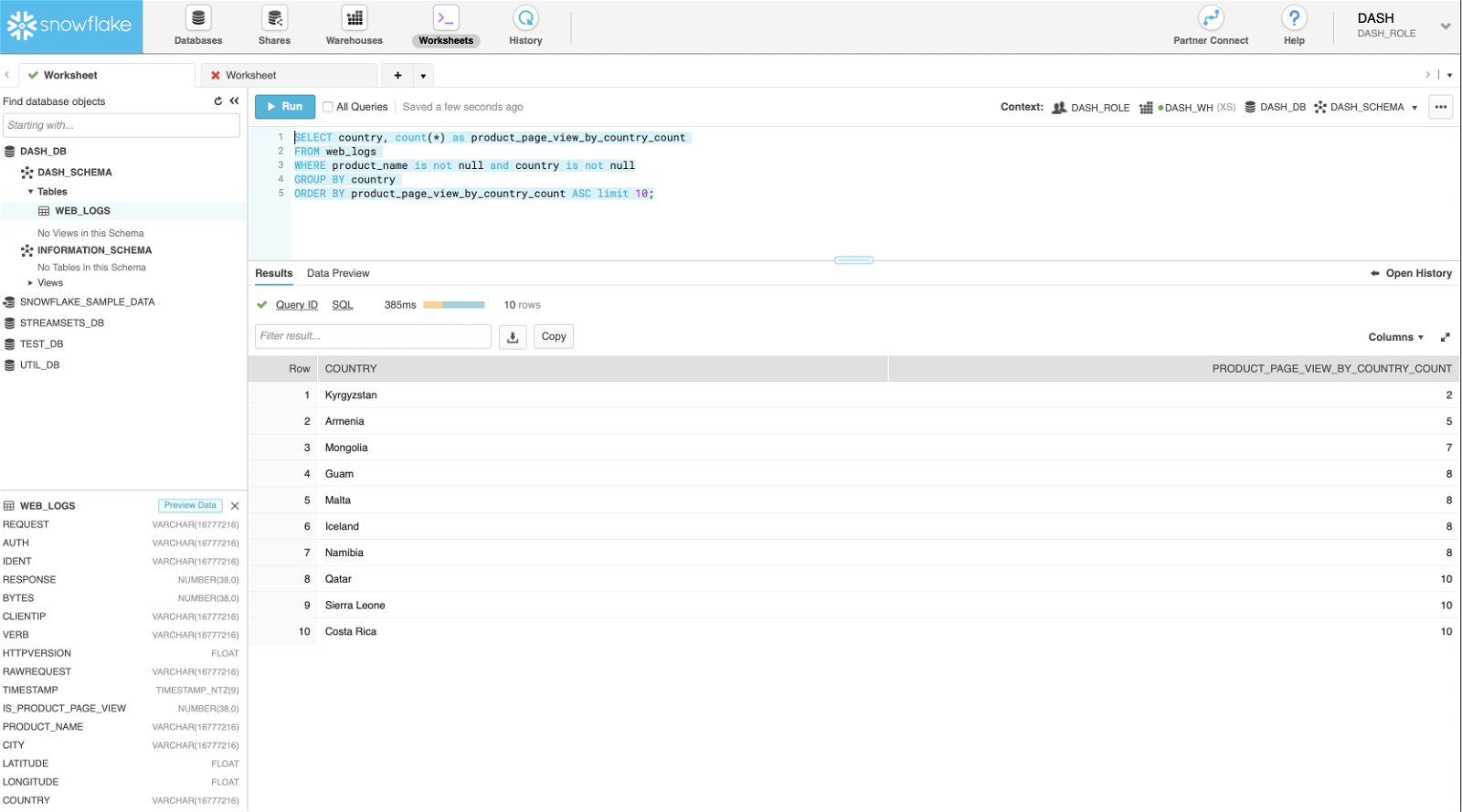
Bottom 10 countries by product page views
SELECT country, count(*) as product_page_view_by_country_count FROM web_logs WHERE product_name is not null and country is not null GROUP BY country ORDER BY product_page_view_by_country_count ASC limit 10;
Summary | Accelerate Your Journey to a Cloud Data Warehouse
In this article, you’ve learned how easy it is to use StreamSets for Snowflake integration to accelerate your journey to the Snowflake cloud data warehouse.
To take advantage of this and other integrations, get started today with StreamSets to design, deploy, and operate smart data pipelines.