Data pipelines are meant to transfer data from a source or legacy system to a target system. Easy right? Well not so much. As a Data Engineer, it’s our job to be responsible for multiple different data pipeline architecture decisions during the design phase.
Answering questions like, what are the source/s and target/s for this data? Is this data coming in a streaming or batch fashion? How are we transforming this data? Do we need to persist the raw data somewhere for analytical or machine learning purposes? All these things just scratch the surface from a Data Engineering perspective. To make matters more difficult, each data pipeline might be unique based on the requirements given for a project or for a specific objective.
To make matters simple, we are going to zoom out and discuss the main processes of high-level architectures and tools associated with them to help simplify the overall steps in building a robust data pipeline architecture.
About the author: Drew Nicolette is a Data Engineer who has spent all of his career working in the public sector, building out big data solutions to help warfighters and soldiers on the ground to capture valuable data insights. On a personal level, he enjoys playing chess and staying active. He also loves to learn and share his knowledge on new cutting-edge technologies in the Data Engineering realm.
Data Pipeline Architecture
Data pipeline architecture can refer to both a pipeline’s conceptual architecture or its platform architecture. I’ll be diving deeper into conceptual architecture and briefly cover tools towards the end of my article that can be used.
Depending on project requirements, us as Data Engineers can be connecting to a variety of different data sources. Each of those data sources can be used independently from one another or combined to enrich the data before moving it into a target data store. Based on how the source data is generated, data pipeline architectures can come in three different forms.
Batch vs. Streaming vs. Combination
- Batch Architecture
A batch pipeline is designed typically for high volume data workloads where data is batched together in a specific time frame. This time frame can be hourly, daily, or monthly depending on the use case. The data formats consumed might consist of files like CSV, JSON, Parquet, Avro and files might be stored in different cloud object stores or data stores of some kind. - Streaming Architecture
A streaming pipeline is designed for data that gets generated in real time or near real time. This data is crucial in making instantaneous decisions and can be used for different IoT devices, fraud detection, and log analysis. - Streaming/Batch Architecture
This architecture is called lambda architecture and is used when there is a need for both batch and streaming data. Although a lot of use cases can be handled by using one or the other, this gives us more flexibility when designing our overall architecture.
Before deciding which data pipeline architecture or combination of architectures to pursue, we first need to generalize and ask a couple simple questions. These questions include the kind of data we are connecting to, the changes we need to make to that data, and what’s the end state for that data.
Based on the answer to the first question, the ingestion might be either real time or not real time.
Real Time vs. Non-Real Time
- Real Time
Real time data is data that comes in millisecond to second latency. To keep up with the data velocity, some ETL tools can’t be leveraged and/or don’t have the capabilities to keep up. Common real time streaming software’s that are being leveraged today are Apache Kafka and Amazon Kinesis. - Non-Real Time
This kind of data can take anywhere from hours to days to years to be created. In this scenario, the traditional ETL approach might be useful to extract the data, transform and clean it, and then load it into a target data store of choice. As of recently, ELT has become a lot more popular though. Compared to ETL, ELT allows an organization to practically replicate the data over to their environment and then run whatever transformations they need on that raw data to capture valuable data insights.
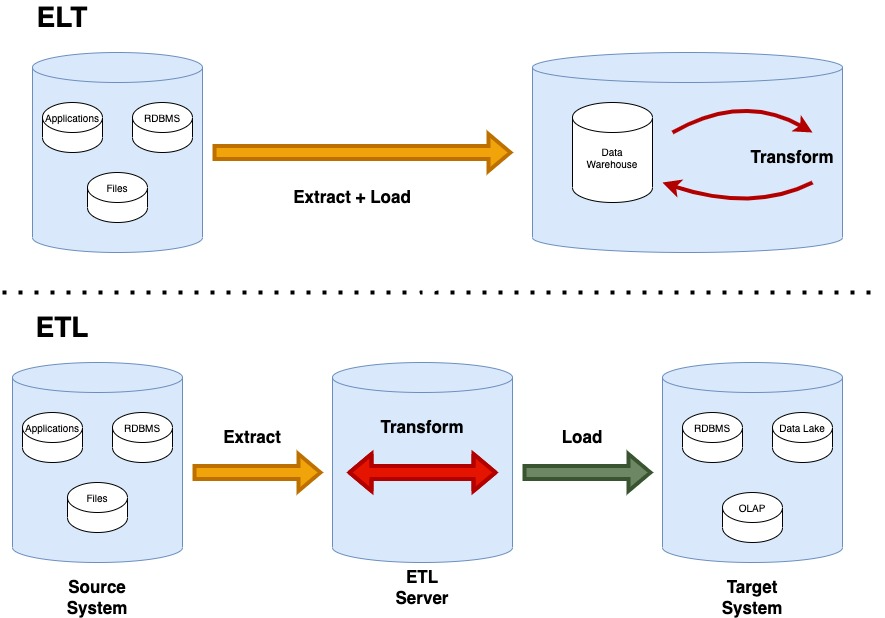
After figuring out whether the data is real time or not, we need to think about how we are going to process that data.
Users can use a multitude of ETL tools to ingest non-real time data. Things to keep in mind when picking an ETL tool for your use case:
- How easy is it to integrate with other data sources and data sinks?
- Does it offer data pipeline monitoring for out-of-the-box visibility?
- How easily can the tool transform your data?
- Does the tool scale or operate under high amounts of data stress?
On the contrary, real time data processing is a totally separate architecture. Here, we not only need to keep up with the demand of data that is being produced, but must also have monitoring capabilities and failure handling in place in case of network issues. If something goes wrong, this can significantly impact business procedures that are dependent on this data to make real time business decisions. Not only should we accommodate a streaming data architecture, but also one that is highly available so we can mitigate the risk of the pipeline failing.
When I discovered StreamSets, I was surprised to learn that StreamSets is the only data integration platform that supports all data movement (batch, streaming, CDC) in a single environment. StreamSets allows a Data Engineer to easily build and visualize data pipelines that are being fed into a model. It’s essential in instrumenting multiple aspects of the data pipeline lifecycle and provides an easy to use GUI to get up and running quickly.
Additional tools that can be leveraged for both ingesting real time and non-real time data are:
- Apache Spark: Batch and/or real time data processing engine that allows Data Engineers to process big data using in-memory computing across a cluster.
- Apache Kafka: Distributed pub-sub messaging system to handle real-time data for streaming and pipelining.
Data Usage Considerations for Data Pipeline Architecture
Last, is looking at the end state of the data and what the intended use of that data is going to be. If the data is going to be used for Machine Learning and Data Science purposes, it might be best to persist the raw data into a data lake so Data Scientists can train and make valid predictions on that data. However, if it’s intended to be used for data analysis purposes, cleaning and transforming the data in the data processing step and then storing it in a data warehouse like SnowFlake or BigQuery might be the most optimal solution.
I have come across scenarios of using a hybrid approach too. Sometimes the raw data needs to be stored for future use in a data lake while the transformed data gets pushed to a database where a reporting/business intelligence software is leveraged to create successful reports and dashboards.
Key Takeaways
Moving data can get complicated quickly if you aren’t familiar with creating a robust data pipeline architecture. If you were to get anything out of this article, I recommend that you solicit as many requirements as you can up front before determining the proper data pipeline architecture.
Keep in mind that requirements change and so does technology. Building a framework that can innovate, handle change, and allow for multiple use cases is ideal. For me personally, I like leveraging dataops tools like StreamSets that can abstract a layer of data processing for me and allow myself as a Data Engineer to spend more time on making sure my pipelines are processing data efficiently, are scalable, and are highly available. I don’t have to worry about building new data source connectors or a custom transform component because I know there are out-of-the-box capabilities within the platform that have been developed to help me out in doing so.
The simpler your data pipeline architecture the better that way the architecture can be sustained and also evolve to use technology we don’t even know exists yet.
