This blog post was updated March 14, 2023
Data pipeline architecture refers to the design of systems and schema that help collect, transform, and make data available for business needs. This data pipeline architecture involves tools and technologies for data ingestion, transformation, monitoring, testing, and loading into systems where it can be analyzed, reported on, and otherwise used.
Because organizational data needs vary, data pipeline architecture may differ as well. For instance, an organization needing real-time analysis may employ a streaming pipeline architecture over a batch ETL architecture. However, organizations can use similar design patterns for identical use cases. Data pipeline design patterns help create consistent, reusable pipelines for business.
What Is Data Pipeline Architecture? The Basics Explained
A data pipeline architecture refers to the design of tools and processes that help transport data between locations for easy access and application to various use cases. These use cases may be for business intelligence, machine learning purposes, or for producing application visualizations and dashboards. Data pipeline architecture aims to make the data pipeline process seamless and efficient by designing an architecture that helps improve the functionality and flow of data between various sources and along the pipeline.
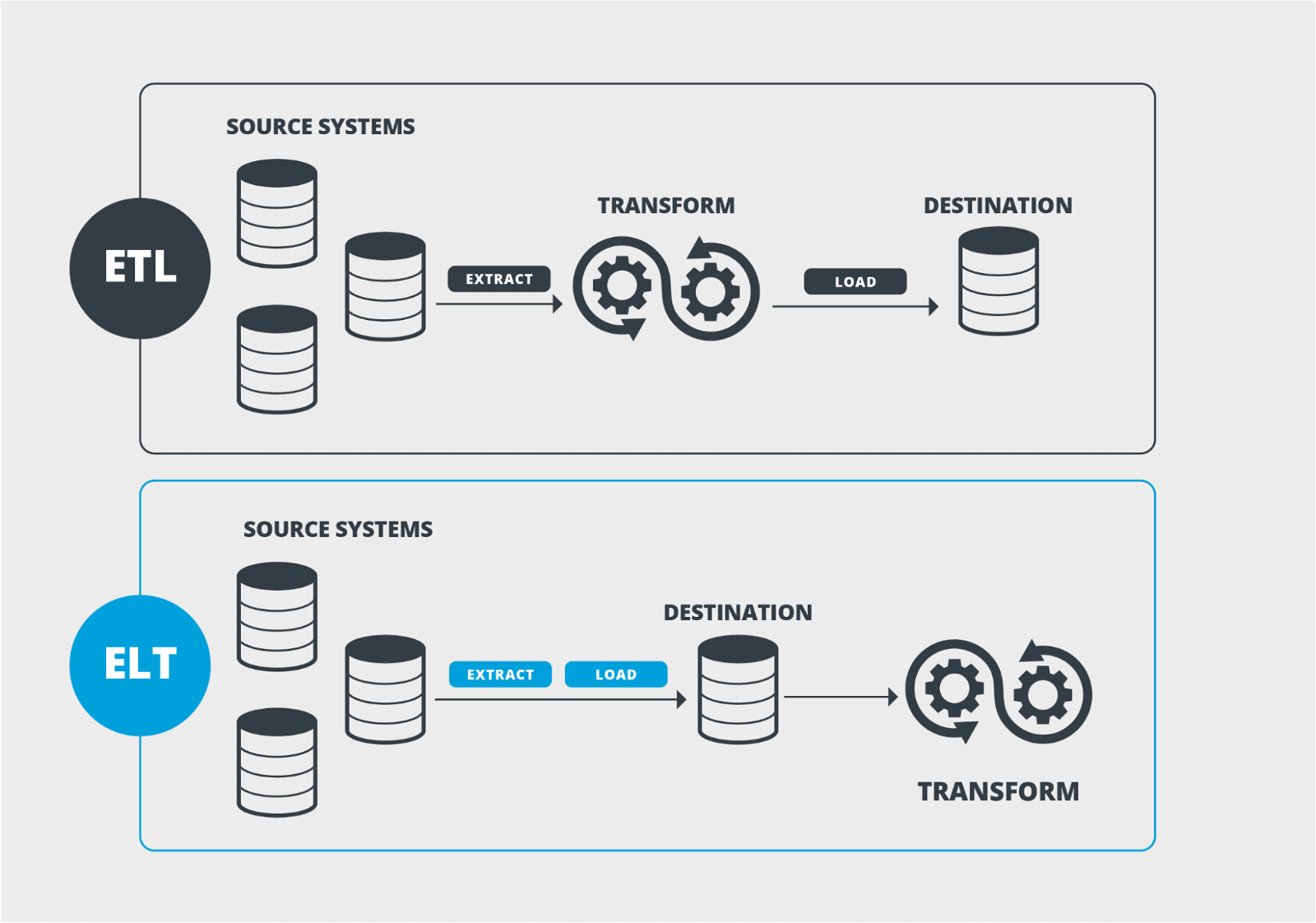
Types and Examples of Data Pipeline Architecture
Batch Architecture
A batch pipeline is designed typically for high volume data workloads where data is batched together in a specific time frame. This time frame can be hourly, daily, or monthly depending on the use case.
The data formats consumed might consist of files like CSV, JSON, Parquet, Avro and files might be stored in different cloud object stores or data stores of some kind.
For example, let’s say your company generates sales transactions that are recorded in an operational database. Your business analysts want this data for analysis so you set up a pipeline that extracts and processes all sales transactions from the database at the end of each day for storage in your data warehouse where analysts can work with the data through dashboards.
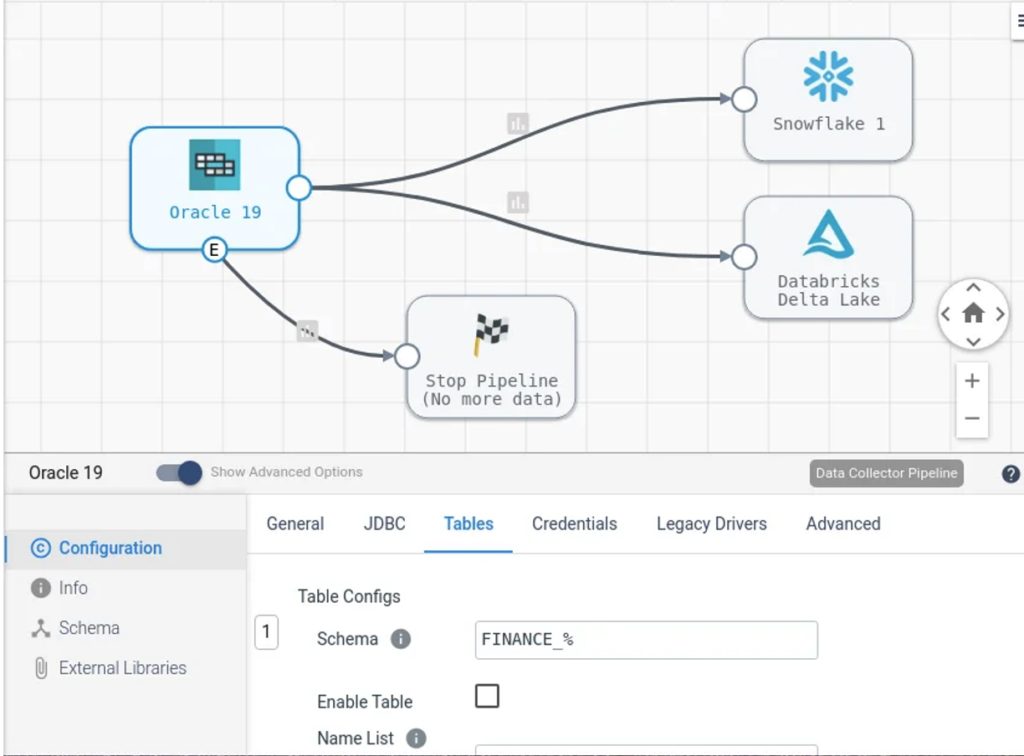
You can see an example of a batch data pipeline architecture with this sample StreamSets pipeline for migrating data from an on-premise database to a cloud warehouse.
Streaming Architecture
A streaming pipeline is designed for data that gets generated in real time or near real time. This data is crucial in making instantaneous decisions and can be used for different IoT devices, fraud detection, and log analysis.
For example, credit card companies rely on a streaming data pipeline architecture to continuously stream transaction data to detect irregularities and stop fraud before it happens. Similarly, applications present recommendations to a customer based on their real-time choices leading to better customer experience (a la Netflix, Amazon, or YouTube).
You can see how StreamSets helps you design a data pipeline within a streaming architecture in the following posts:
- Send Kafka Messages To Amazon S3 | StreamSets
- Creating Dataflow Pipelines with Amazon Kinesis | StreamSets
- Sentiment Analysis: Microsoft SQL Server 2019 Big Data Cluster And StreamSets DataOps Platform
Lambda Architecture (Streaming/Batch)
This architecture is called lambda architecture and is used when there is a need for both batch and streaming data. Although a lot of use cases can be handled by using one or the other, this gives us more flexibility when designing our overall architecture.
The classic example of a lambda pipeline architecture is in stock trading. Traders need real-time processing to make decisions about which securities to buy and sell throughout the day. This requires processing a massive amount of data very quickly, which stream processing excels at.
But analysts and stock traders also need highly accurate data that they can later audit, like financial reports. In this particular example of lambda architecture, stock traders can get instant processed data from the speed layer (data streaming layer) and get more complete data from the batch layer.
The Importance of Data Pipeline Architecture
- Saves time with reusability: A single pipeline architecture can be replicated and applied for similar business data needs, leaving more time for engineers to focus on other tasks.
- Data consolidation: Data from various sources are combined and consolidated in a single destination through pipeline architecture.
- Improved functionality: Data pipeline architecture helps establish a seamless workflow of data, which prevents data silos and enables teams to have access to data they need, which helps improve day-to-day business functions.
- Allows easy data sharing between groups: Most data processes undergo similar transformation processes before usage. For example, data cleaning is an essential part of transformation and must occur before use in most cases. Establishing a clear pipeline workflow automates this process and enables easy data sharing between different teams.
- Accelerated data lifecycle processes: Data pipeline architecture involves automation in an organized manner with minimal human effort. Hence, data processes occur faster with a reduced risk of human-prone errors.
- Standardization of workflows: Data architecture helps define each pipeline activity, making monitoring and management more effortless. Also, because each step follows a well-defined process, it helps monitor and identify substandard steps in the pipeline.
Challenges of Data Pipeline Design
Designing data pipelines can be challenging because data processes involve numerous stop points. As data travels between locations and touchpoints, it opens the system to various vulnerabilities and increases the risk of errors. Here are some challenges facing efficient pipeline design:
- Increasing and varied data sources: The primary aim of data pipelines is to collect data from various data sources and make it available via a single access point. However, as organizations grow, their data sources tend to increase, hence the need for a seamless design to integrate new data sources while maintaining scalability and fast business operations. Integration of new data may be complex due to the following reasons:
-
- The latest data source may differ from the existing data sources.
- Introducing a new data source may result in an unforeseen effect on the data handling capacity of the existing pipeline.
- Scalability: It’s a common challenge for pipeline nodes to break when data sources keep increasing, and data volume increases, resulting in data loss. Data engineers usually find it challenging to build a scalable architecture while keeping costs low.
- The complexity resulting from many system components: Data pipelines consist of processors and connectors, which help in the transport and easy accessibility of data between locations. However, as the number of processors and connectors increases from various data integrations, it introduces design complexity and reduces the ease of implementation. This complexity, in turn, makes pipeline management difficult.
- The choice between data robustness and pipeline complexity: A fully robust data pipeline architecture integrates fault detection components at several critical points along the pipeline and mitigation strategies to combat such faults. However, adding these two to pipeline design adds complexity to the design, which results in complex management. Pipeline engineers may become tempted to design against every likely vulnerability, but this adds complexity quickly and doesn’t guarantee protection from all vulnerabilities.
- Dependency on other vital factors: Data integration may depend on action from another organization. For example, Company A cannot integrate data from Source B without input from Company B. This dependency may cause deadlocks without proper communication strategies.
- Missing data: This problem significantly reduces data quality. Along the data pipeline, files can get lost, which may cause a significant dent in data quality. Adding monitoring to pipeline architecture to help detect potential risk points can help mitigate this risk.
Data Pipeline Design Patterns
These are templates used to create data pipeline foundations. The data pipeline design choice depends on multiple factors like how data is consumed/received, business use cases, and data volume. Some common design patterns include:
- Raw Data Load: As the name suggests, raw data load involves the movement and loading of raw data from one location to another. The data movement in this architecture pattern could be between databases or from an on-premise data center to the cloud. Since this design pattern involves moving raw data, it involves only the extraction and loading process. Raw data loading can be slow and time-consuming, especially as data volume increases. This design pattern works best for on-time operations and is not ideal for recurring situations. Origin(DB, on-premise data center, cloud) ———> Extract ———> Load ———> Destination
- Extract, Transform, Load (ETL): This is the most popular design pattern for loading data into data warehouses, lakes, and operational data stores. It involves the extraction, transformation and loading of data from one location to another. Most ETL processes use batch processing which introduces latency to operations. ETL works for most data integration processes where data sources undergo integration at different times.
- Streaming ETL: This pattern is identical to the standard ETL pattern, but where data stores act as the origin for the traditional ETL pattern, data streams become the origin in this case. The process involves parsing and filtering, followed by transformation and loading into a data lake. Streaming ETL utilizes a streaming processing tool like Apache Kafka or StreamSets Data Collector Engine to perform the complex ETL process.
- Extract, Load, Transform (ELT): A slight variation from the traditional ETL process, this architecture collects data and then loads it into a target destination before transforming. By placing the transformation process as the last process in the workflow, there is a reduced latency than the ETL design. A major concern for this design is its effect on data quality and violation of data privacy rules. When data gets loaded without certain transformation processes that hide sensitive data, it may expose sensitive information.
- Change, Data, Capture (CDC): This design pattern introduces freshness to data processed using the ETL batch processing pattern. By detecting changes occurring during the ETL process and sending to message queues using CDC, they’re made available for downstream processing, which processes them in mini-batches, making data available immediately.
- Data Stream Processing: This pattern is ideal for feeding real-time data to high volume and high-performance applications like the Internet of Things(IoT) and financial applications. Data arrives from a string of devices in a continuous stream, gets parsed and filtered into records of interest and processed before being sent to various destinations like dashboards feeding real-time applications.
Data Pipeline Architecture for AWS
An AWS data pipeline architecture consists of building blocks like task runners, data nodes, activities, actions, and preconditions. Organizations can spin up resources like EC2 instances using CloudFormation templates or the command line tool. Organizations can store and process large volumes of data with AWS cloud S3 buckets for transfer into AWS cloud data warehouse solution– Amazon RedShift.
Using Virtual Private Cloud (VPC) and other tools like Web Application Firewall (WAF) also helps isolate data resources to help with the security of pipelines. However, Amazon Redshift offers no out-of-the-box column-level data encryption, which may open the system up to vulnerabilities.
Data Pipeline Architecture for Azure
Azure data Synapse offers over 90+ connectors which allow developers and analysts to integrate more data sources without writing code. Azure synapse relies on Azure Data Lake as its storage option and integrates with Azure data warehouse for its analytics needs or Apache spark for its Big data needs. Azure also offers unlimited scaling.
Azure offers data encryption in-transit and at rest, in addition to security measures like row-level security, column-level security, and data masking to help ensure data security.
Data Pipeline Architecture for Kafka
Kafka employs a decoupled distributed messaging system that can process high volumes of data at low latency and high performance. Organizations using Kafka connect their data sources and use Kafka to stream and feed Hadoop BigData lakes. Kafka is compatible and can work with Storm, HBase, Flink, StreamSets and Spark for real-time ingesting, analysis, and stream data processing.
Data Pipeline Architecture Best Practices
Designing a pattern for your data engineering processes can be challenging. Here are some best practices to keep in mind when designing a pipeline architecture:
- Monitoring is vital: End-end monitoring ensures adequate pipeline security and improves trust in data quality. By automating monitoring with specific tools, engineers can identify vulnerable points in their design and mitigate these risks immediately after they happen.
- Incorporate testing in the design pattern: Frequent testing helps identify risks along the system development cycle. Before implementing a design pattern, data engineers test or preview pipeline operations to screen for vulnerabilities and ensure a seamless process that produces consistent data with excellent quality.
- Perform data transformation in small, incremental steps: Pipeline design architecture and implementation should occur in small, iterative steps. It should follow best engineering practices that break down tasks into smaller ones and run these little tasks to observe their performance before incorporating these components together. For example, transformation processes are usually complex, and a problem in one step may affect later stages in the pipeline. By breaking down such tasks and testing individually, we can be confident in the results of our pipeline.
- Design with scalability: There’s always the chance that data needs may change as the business evolves with time. For example, data volume may grow exponentially, and engineers should factor this into their pipeline architecture. Combining proper monitoring with alert systems when operating near its maximum capacity and weaving in autoscaling at the design level are approaches that help with scalability.
- Ensure sustainability and management don’t become too complex: As data sources and nodes increase, it introduces complexity to the pipeline design. Engineers should focus on maintaining simplicity in design while following best practices. Before designing a pipeline, every process should undergo screening and deem necessary before weaving into the pipeline architecture. This practice helps maintain simplicity and reduces many unnecessary scripts that complicate future maintenance.
- Design should be predictable to improve data traceability: Data pipeline design should follow a predictable pattern and not involve many dependencies. Dependencies add a layer of complexity, and problems resulting from dependencies can be hard to trace when they occur. Reducing dependencies makes the data pipeline path easier to follow and trace.
Quality of Data from Pipelines
Data-driven organizations rely on quality data to make informed business decisions. However, the quality of data from pipelines depends on the design and use of tools and technologies used to build such pipelines. Data pipeline architecture helps create a repeatable and sustainable process for creating reliable pipelines that can scale with the business. A decoupled architecture provides enhanced levels of agility and scalability to modern data pipeline architectures.
StreamSets DataOps Platform allows organizations to easily build data pipelines at scale to fit their business needs. The easy-to-use user interface and multiple prebuilt connections also enable quick data integrations, which allows organizations to set up pipelines faster and get immediate access to the data value.
