Explained: Stream Processing, Streaming Data,
and Streaming Data Pipelines
How stream processing and streaming data pipelines turn digital actions into real-time analytics
What Is Streaming Data?
Streaming data is the continuous flow of information from disparate sources to a destination for real-time processing and analytics.
What is a data stream example?
Real-time data streaming is beneficial when new data is generated continually. For example, credit card companies can use streaming transaction data to detect irregularities and stop fraud before it happens. Or applications can present recommendations to a customer based on their real-time choices leading to better customer experience (a la Netflix, Amazon, or YouTube).
Personalizing a web experience like this, calculating optimal truck routes, or reporting on sleep patterns are examples of real-time analytics. Streaming data used to promote a product add-on during checkout, auto-drive the truck, or soothe a baby back to sleep are examples of real-time applications.
For the purposes of this article, we will focus on streaming data used for analytics, including sentiment analysis, predictive analytics, and machine learning/AI.
Streaming Data and Real-time Analytics
To put streaming data into perspective, each person creates 2.5 quintillion bytes of data per day according to current estimates. And data isn’t just coming from people. IDC estimates that there will be 41.6 billion devices connected to the “Internet of Things” by 2025. From airplanes to soil sensors to fitness bands, devices generate a continuous flow of streaming data for real-time analytics and applications.
Everyone wants their slice of that data to do what they do better:
- Sales and marketing can offer real-time suggestions for a next best action
- Operations and customer service cut repair and build time with more efficiency
- Security and compliance can detect fraud and take action before damage is done
They depend on a continuous flow of data coming from sources that are subject to change and often out of IT’s control. On the destination side of the data value chain, data consumers use many different systems, designed for particular types of analysis. In the middle is the data engineer, tasked with creating connections and making sure data stays correct and consistent.
So, what is the benefit of streaming data?
To put it simply, the real-time nature of stream data processing allows data teams to deliver continuous insights to business users across the organization.
How Data Processing Works: Preparing Data for Analytics
Before data can be used for analysis, the destination system has to understand what the data is and how to use it. Data flows through a series of zones with different requirements and functions:
Raw Zone
The raw zone stores large amounts of data in its originating state, usually in its original format (Avro, JSON or CSV, for example). Data come into the raw zone through a process of ingestion as streaming data, a batch of data, or through a change data capture process where only changes to previously loaded data are updated.
Clean Zone
The clean zone (or the refined zone) is a filter zone where transformations may be used to improve data quality or enrich data. Common transformations include data type definition and conversion, removing unnecessary columns, masking identifiable data, etc. The organization of this zone is determined by the business needs of the end users, for example, the zone may be organized by region, date, department, etc.
Curated Zone
The curated zone is the consumption zone, optimized for analytics rather than data processing. This zone stores data in denormalized data marts and is best suited for analysts or data scientists who want to run ad hoc queries, analysis, or advanced analytics.
Conformed Zone
The conformed zone houses data transformed and structured for business intelligence and analytics queries.
From Apache Kafka to Object Stores
Apache Kafka is an open source distributed event streaming platform, known as a “pub/sub” messaging system. A streaming data source starts publishing or streaming data and a destination system subscribes to receive the data. The publisher doesn’t wait for subscribers and subscribers jump into the stream when they need it. Kafka is fast, scalable, durable and was a pillar of on-premises big data deployment.
Cloud platforms introduced a new way of storing unstructured data called an object store. Producers became decoupled from consumers, and the cost of storage became negligible. You could keep all the data you wanted as objects to be accessed when needed. For example, Amazon Kinesis integrates directly with Amazon Redshift (an analytics database) and Amazon S3 for streaming data.
Learn more about how Kinesis compares to Kafka for data engineers. Or, take a look at this article for an example of a Kafka-enabled streaming pipeline in StreamSets.
Stream Processing vs Batch Processing
To make streaming data useful requires a different approach to data than traditional batch processing data integration techniques. Think of batch processing as producing a movie. The production has a beginning, middle, and an end. When the work is complete, there is a whole, finished product that will not change in the future. Stream processing is more like an episodic show. All of the production tasks still happen, but on a rolling time frame with endless permutations.
In batch processing, data sets are extracted from sources, processed or transformed to make them useful, and loaded into a destination system. ETL processing creates snapshots of the business in time, stored in data warehouses or data marts for reporting and analytics. Batch processing works for reporting and applications that can tolerate latency of hours or even days before data becomes available downstream.
With the demand for more timely information, batches grew smaller and smaller until a batch became a single event and stream processing emerged. Without a beginning or an end, sliding window processing developed so you could run analytics on any time interval across the stream.
Handling both stream and batch processing has become essential to a modern approach to data engineering. At DNB, Norway’s largest financial services group, data engineers use streaming instead of batch wherever possible as a data engineering best practice.
“We encourage our data engineers to use streaming mode wherever possible. The downstream pipeline can be run as per the requirement, but it always gives us the option of running it more frequently than once a day to a near real-time by using this approach.”
Stream Processing Frameworks
Stream processing frameworks give developers stream abstractions on which they can build applications. There are at least 5 major open source stream processing frameworks and a managed service from Amazon. Each one implements its own streaming abstraction with trade-offs in latency, throughput, code complexity, programming language, etc. What do they have in common? Developers use these environments to implement business logic in code.
- Apache Flink for stateful computing over data streams
- Apache Ignite for high performance computing with in-memory speed
- Apache Samza for stateful applications that process data in real-time
- Apache Spark for scalable, fault-tolerant streaming applications
- Apache Storm for distributed real-time computations
- Amazon Kinesis Data Streams for real-time managed data streaming
Apache Spark is the most commonly used of these frameworks due to its native language support (SQL, Python, Scala, and Java), distributed processing power, performance at scale, and sleek in-memory architecture. Apache Spark processes data in micro-batches.
Design Considerations
Streaming Data Pipeline Examples
A data pipeline is the series of steps required to make data from one system useful in another. A streaming data pipeline flows data continuously from source to destination as it is created, making it useful along the way. Streaming data pipelines are used to populate data lakes or data warehouses, or to publish to a messaging system or data stream.
The following examples are streaming data pipelines for analytics use cases.
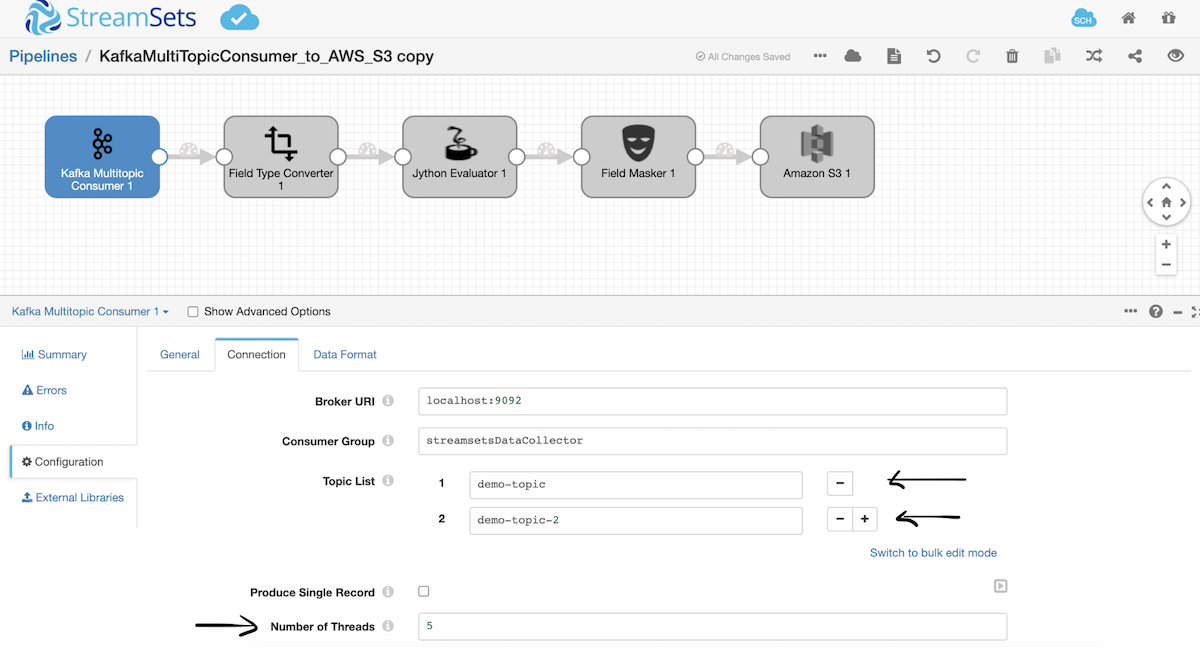
Sending Kafka Messages to S3
Where your data comes from and where it goes can quickly become a criss-crossing tangle of streaming data pipelines. Streaming data pipelines that can handle multiple sources and destinations allow you to scale your deployment both horizontally and vertically, without the complexity. Find out how to manage large workloads and scale Kafka messages to S3.
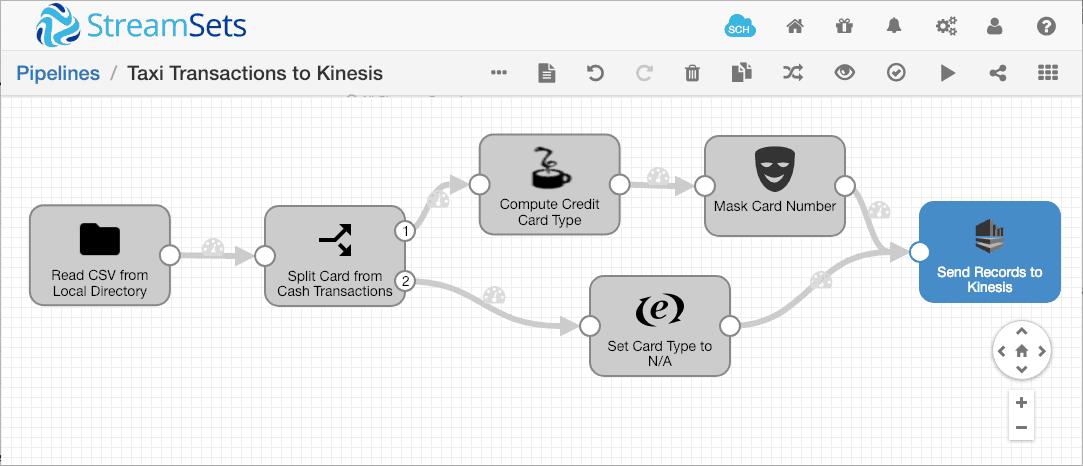
Protecting Credit Card Data in an Amazon Kinesis Stream
Amazon Kinesis, a supported real-time streaming service from Amazon, may be a good choice for populating S3 and Redshift and for use in cloud analytics systems. This streaming data pipeline for Kinesis uses credit card type as a partition key to apply data masking if a credit card is found in the file then publishes the information to the Kinesis producer.
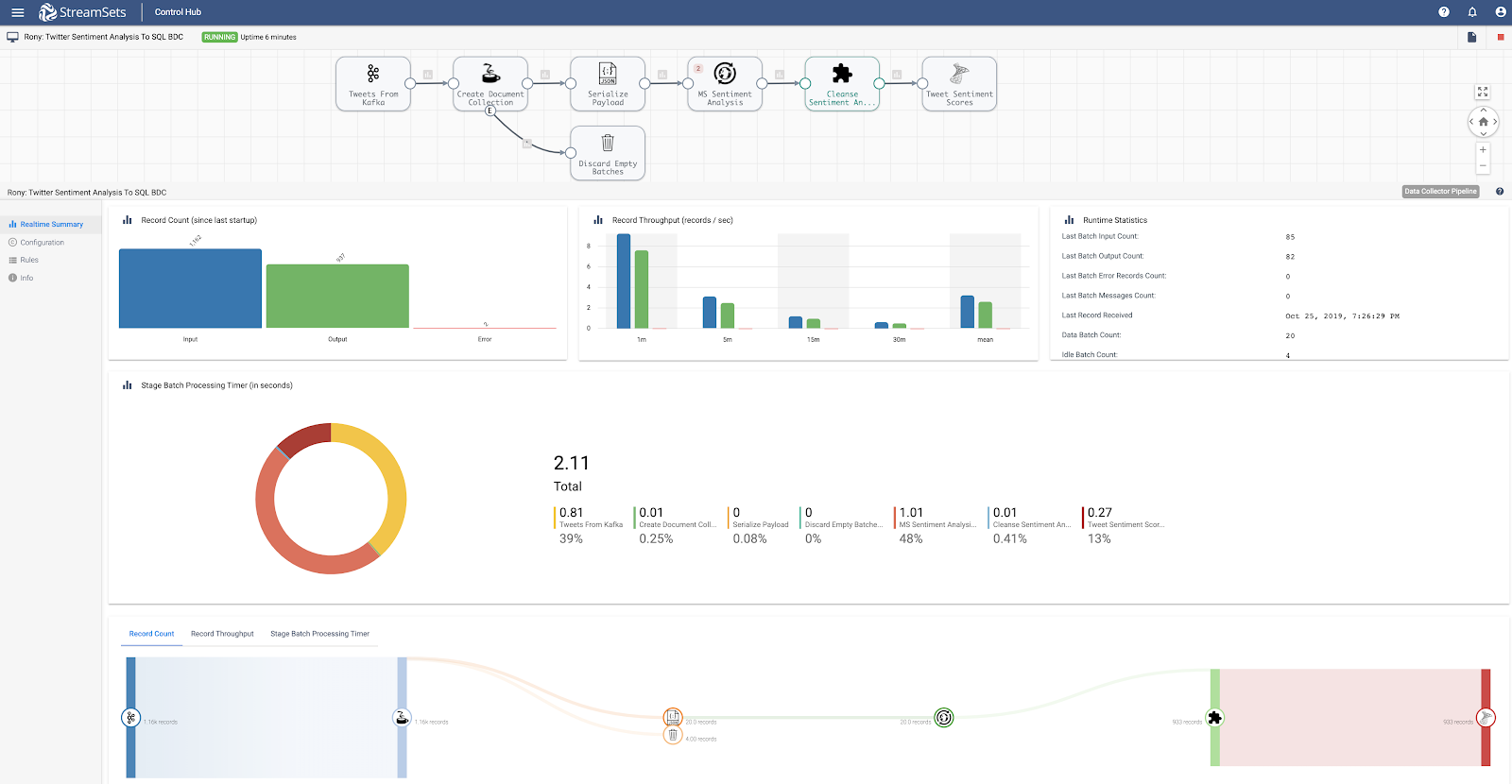
From Twitter to Kafka to Machine Learning on Azure
Tracking mentions on Twitter of your favorite football team may be interesting to a fan, but attitudes about teams might be used to determine an advertising budget investment. This sentiment analysis data pipeline allows you to ingest data to Apache Kafka from Twitter for streaming, prepare it for the Azure Sentiment Analysis API, then store the data to be queried to your heart’s content.
Machine Learning Data Pipelines with Tensorflow
Machine learning applies algorithms to data to discover insights from large and unstructured data sets. For example, breast cancer tumor data could be analyzed and classified as either benign or malignant for all kinds of environmental and population analysis to better understand treatment and prevention. This streaming data pipeline shows you how to ingest data and generate predictions or classifications using real-time machine learning with Tensorflow.

Challenges to Streaming Data
Before you choose a tool or start hand coding streaming data pipelines for mission critical analytics consider these decision points.
The Tyranny of Change
Data will drift and you need a plan to handle it. Schemas change, semantics change, and infrastructure changes. When your analytics depend on real-time data, you can’t take a pipeline out of production to update it. You need to make updates and preview changes without stopping and starting the data flow. Better yet, you need the ability to automate data drift handling as much as possible to ensure continuous data.
What about Hand Coding?
While technologies like Kafka and Spark simplify many aspects of stream processing, working with any one of them still requires specialized coding skills and plenty of experience with Java, Python, Scala, and more. Finding skilled developers in any single stream processing technology is difficult, but building a team with expertise in more than one? Not for everyone’s budget. Hand coding limits your team’s ability to scale and democratize data access.
The Wild Innovation Ride
As new stream processing frameworks solve streaming data challenges, you need to be able to adapt and optimize your data pipelines. Cloud-based solutions work well natively, but what about streaming data across platforms or to multiple destinations? You might have to go back to hand coding your own connectors, or end up with multiple, separate systems to monitor and maintain.
Follow the Business Logic
These questions focus on the “how” of the data pipeline implementation details. How will data get from point A to point B and be useful? What happens when there are lots of As, lots of Bs, and the data never stops flowing? How do you stay ahead of the “what” without getting bogged down in the “how”?
The majority of business logic that drives the modern enterprise resides in the integration between 1000s of specialized applications across multiple platforms. Your analytics and operations become the most vulnerable points in modern business operations.
A data engineering approach to building smart data pipelines allows you to focus on the what of the business logic instead of the how of implementation details. Ideally, your streaming data pipeline platform makes it easy to scale out a dynamic architecture and read from any processor and connect to multi-cloud destinations.
Building Streaming Data Pipelines
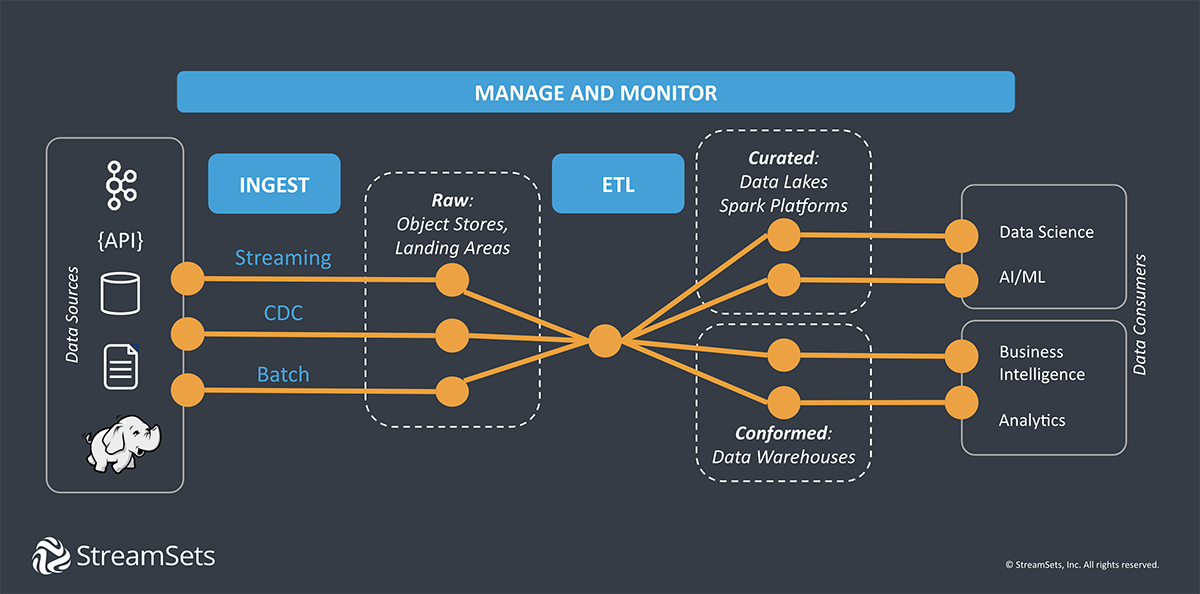
Data streams are large, varied, often unstructured, and relentless. They may or may not be under your control. Real-time streaming architectures have lots of moving pieces, and they come in a diverse (and rapidly evolving) range of configurations.
Yet, real-time data offers a rich new vein of information to tap for insights. It’s the difference between waiting for box office results to determine next quarter’s release schedule, and automatically starting a next episode or recommendation on a streaming movie channel.
The less you have to worry about the “how” of your data stream, the more you can focus on the “what” of using it for growth and innovation in your business. Keeping a continuous flow of data for both analytics and exploration is the job of data engineering and streaming data pipelines.
The StreamSets data engineering platform is dedicated to building the smart data pipelines needed to power DataOps across hybrid and multi-cloud architectures. Build your first data pipeline today!