When you focus on the theory of democratized data, it’s easy to get idealistic.
In this world of theory, practical realities fall by the wayside. The backend, where data pipeline tools and solutions live, quickly becomes an afterthought.
But, forced to live in the world of practical application — where scalability, compliance, and quality rule — data engineers know better.
They know all too well the issues that come with democratized data: ballooning volumes of heterogeneous data sets scattered across an opaque and growing collection of tools serving diverse users with ever-evolving needs.
Fortunately, coupled with the right people and processes, data pipeline tools can help organizations tease order out of the chaos.
A Brief History of Extracting Value From Data at Scale
The earliest incarnation of a data pipeline tool ran on mainframe computers, processing what were once considered large volumes of data in batches.
Database management systems followed, making it easier to store and manage large volumes of data, which began the age of Extract, Transform, and Load (ETL) tools.
ETL remained the dominant data pipeline solution until the 2000s when cloud computing led to the development of open-source frameworks like Hadoop, Spark, and Kafka. This facilitated the growth of real-time data processing capabilities.
Alongside these innovations, a suite of complementary data governance and metadata management solutions developed.
Together, these tools made it easier for engineers to extract, clean up, and consolidate data of all kinds into centralized locations, which is why many platforms (like StreamSets) combine them.
The Stubborn Problems in Data Engineering
This continuously developing set of tools and technologies helped data engineers improve scalability, agility, and cost-efficiency while managing runaway data volumes, velocity, and variety.
Even so, three key data engineering challenges persisted:
- The data supply chain is increasingly fragmented beyond the confines of the IT department, making data architecture increasingly dynamic yet opaque.
- Scarce engineering resources are overwhelmed with demands to quickly support diverse lines of business.
- The inability to balance the competing needs of innovation and flexibility to change with control.
Dulling the Edge of Double-Edged Sword of Democratized Data
To realize the theoretical potential of fully democratized data, data engineers need solutions that take these challenges head-on. So in the following sections, we’ll break down the challenges and solutions that address them point by point.
Taming the Increasingly Fragmented Data Supply Chain
One of the most problematic fragmentations in the data supply chain exists between modern and legacy environments. Managing these hybrid deployments often requires specialized knowledge and means grappling with — among other things — incompatible data formats and performance issues.
To ease this burden, data engineers need tools that let them centralize hybrid deployment management and gain visibility into how data flows across the enterprise. These capabilities will mitigate the time and effort it takes to manage hybrid deployments and expose hidden problems in enterprise-wide data flows.
Insufficient Resources to Quickly Support Diverse LOBs
One of the most perplexing challenges a data engineer faces is how to transform data from an opaque and growing number of sources, and how to do it at scale.
According to the 2023 SaaS Management Index Report, the average company adds 6.2 new applications per month. That’s 6.2 entirely new data models that data engineers have to figure out how to integrate.
And that’s assuming those engineers know those apps have been added. Further data from that report shows IT controls just 18% of applications in the average software portfolio. By the number of apps, individuals buy 37% of apps, business units buy 45% of apps, and IT buys the rest.
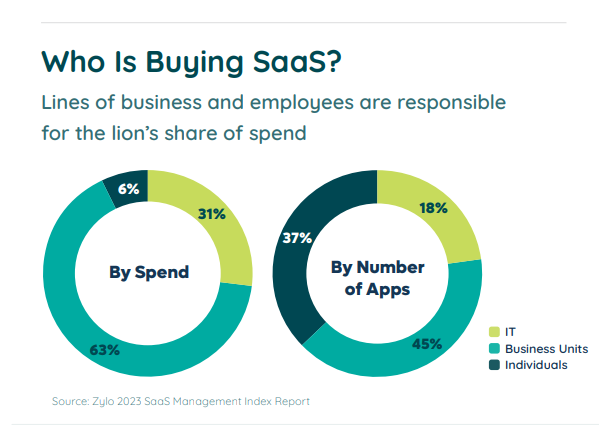
Image Source: https://zylo.com/reports/2023-saas-management-index/
To address these challenges, data engineers need data pipeline tools that enable them to:
- Manage many data sources and targets from a single interface.
- Templatize data pipelines that they can reuse.
- Simplify transformations with extensible drag-and-drop processors, while retaining extensibility.
Getting Ahead of Constant Change
Even if it were possible, just keeping up with constant change simply isn’t enough for a company to fully realize the value of its data.
Yet today, the average data engineer has a large chunk of their time monopolized by maintaining and debugging ad-hoc pipelines.
To shift into a more proactive stance, engineers need dynamic pipelines that don’t break when change is introduced. And they need pipeline fragments with business logic that can be captured, reused, or repurposed.
Why Now for Data Pipeline Solutions
Data engineers’ lack of resources is at least partly to blame for disillusioning what should be an engaged, vibrant workforce.
In a survey of 600 data engineers, 97% of respondents said they were experiencing burnout. 70% said they were likely to leave their company within the next 12 months and 80% have considered leaving their career entirely.
Among the reasons cited for this sad state of affairs:
- 90% of respondents said they frequently receive unreasonable requests.
- 87% said they’re frequently blamed when things go wrong with data analytics
- Half said they spend too much time finding and fixing errors, maintaining data pipelines, and playing catchup with requests.
All this suggests a daunting reality — the data industry is leaving its most talented people behind. But with the right resources, it doesn’t have to be this way.
Tools like StreamSets can ease the burden on data engineers and help them unlock data without ceding control by offering:
- A single interface in which to create, templatize, reuse, and repurpose many different data integration pipelines.
- Simplified transformations without sacrificing performance with extensible drag-and-drop processors.
- Centralized management of hybrid deployments and visibility into system connections.
- Automatic data drift detection to eliminate manual debugging.
