 As well as parsing incoming data into records, many StreamSets Data Collector (SDC) origins can be configured to ingest Whole Files. The blog entry Whole File Transfer with StreamSets Data Collector provides a basic introduction to the concept.
As well as parsing incoming data into records, many StreamSets Data Collector (SDC) origins can be configured to ingest Whole Files. The blog entry Whole File Transfer with StreamSets Data Collector provides a basic introduction to the concept.
Although the initial release of the Whole File feature did not allow file content to be accessed in the pipeline, we soon added the ability for Script Evaluator processors to read the file, a feature exploited in the custom processor tutorial to read metadata from incoming image files. In this blog post, I’ll show you how a custom processor can both create new records with Whole File content, and replace the content in existing records.
One of our community members recently asked a question in the Slack channel:
I can read data via the whole file data format, obtain a stream from /fileRef and convert it into a file. I can then process this file as I need. Is there any way to create a new record with a new changed file?
Although my first reaction was “You can’t do that!”, but a moment’s thought suggested that it is, in fact, possible to create records with new whole file content. The /fileRef field is just an object that implements the FileRef abstract class. A custom processor, written in Java, can provide a class implementing FileRef to do just about anything, as long as it can return a Java InputStream.
Creating Whole File Content
As a quick example, I implemented a custom processor with a FileRef storing its data in a String, and posted it to Ask StreamSets.
In this example, the processor creates a StringFileRef holding some sample data, adds it to a new record and inserts that record into the batch:
public abstract class SampleProcessor extends SingleLaneRecordProcessor {
public static final String DATA = "The quick brown fox jumps over the lazy dog";
...
@Override
protected void process(Record record, SingleLaneBatchMaker batchMaker) throws StageException {
// Emit the input record
batchMaker.addRecord(record);
// Create a new record - we'll use the content of the field '/a' as
// the filename, and some dummy data.
Record newRecord = getContext().createRecord(record);
HashMap<String, Field> root = new HashMap<>();
root.put("fileRef", Field.create(new StringFileRef(DATA)));
newRecord.set("/", Field.create(root));
HashMap<String, Field> fileInfo = new HashMap<>();
fileInfo.put("size", Field.create(DATA.length()));
fileInfo.put("filename", Field.create(record.get("/a").getValueAsString()));
newRecord.set("/fileInfo", Field.create(fileInfo));
batchMaker.addRecord(newRecord);
}
}
StringFileRef itself is almost trivially simple:
public class StringFileRef extends FileRef {
private final String data;
private final Set<Class<? extends AutoCloseable>> supportedStreamClasses = Collections.singleton(InputStream.class);
public StringFileRef(String data) {
// FileRef constructor requires a buffer size
super(data.length());
this.data = data;
}
// We need to indicate what stream classes we support
@Override
public <T extends AutoCloseable> Set<Class<T>> getSupportedStreamClasses() {
return (Set)supportedStreamClasses;
}
// Return an input stream
@Override
public <T extends AutoCloseable> T createInputStream(
Stage.Context context, Class<T> aClass
) throws IOException {
return (T)new ByteArrayInputStream(data.getBytes(StandardCharsets.UTF_8.name()));
}
}
Using this processor in a pipeline with an appropriate destination results in files (or S3 objects) with the expected content:
$ ls /tmp/out/2017-10-27-18/
sdc-24e75fba-bd00-42fd-80c3-1f591e200ca6-1 sdc-24e75fba-bd00-42fd-80c3-1f591e200ca6-3
sdc-24e75fba-bd00-42fd-80c3-1f591e200ca6-2
$ cat /tmp/out/2017-10-27-18/sdc-24e75fba-bd00-42fd-80c3-1f591e200ca6-1
The quick brown fox jumps over the lazy dog
Replacing Whole File Content
Let’s look at another use case – a processor that needs to replace whole file content, and on a more realistic scale than 43 characters!
Our use case is that our incoming files need some custom processing before they are written to the destination. For the purposes of our example, this processing is going to be ROT13 – a simple substitution cipher that replaces each letter of the incoming plaintext data with the letter 13 letters later in the alphabet, rotating past ‘Z’ back to ‘A’. ROT13 is often used in online forums to hide punchlines to jokes, spoilers etc. It is not an encryption mechanism that should be used to protect production data!
The complete custom processor project is on GitHub, but I’ll walk through the highlights here.
As before the FileRef implementation is trivial, just a wrapper around a File object:
// Simple FileRef implementation to allow a custom processor to
// write to a whole file
public class OutputFileRef extends FileRef {
private static final Set<Class<? extends AutoCloseable>> supportedStreamClasses = Collections.singleton(InputStream.class);
private static final int BUFFER_SIZE = 1024;
File file;
public OutputFileRef(String directory, String filename) {
super(BUFFER_SIZE);
file = new File(directory, filename);
}
@Override
public <T extends AutoCloseable> Set<Class<T>> getSupportedStreamClasses() {
return (Set)supportedStreamClasses;
}
@Override
public <T extends AutoCloseable> T createInputStream(
Stage.Context context, Class<T> aClass
) throws IOException {
return (T)new FileInputStream(file);
}
public File getFile() {
return file;
}
}
Rot13DProcessor allows configuration of a directory in which to create files:
@ConfigDef(
required = true,
type = ConfigDef.Type.STRING,
defaultValue = "/tmp",
label = "Directory",
description = "Directory for the temporary output file",
displayPosition = 10,
group = "ROT13"
)
public String directory;
The processor’s init() method checks that it’s possible to write to the configured directory:
// Check we can write to the configured directory
File f = new File(getDirectory(), "dummy-" + UUID.randomUUID().toString());
try {
if (!f.getParentFile().exists() && !f.getParentFile().mkdirs()){
// Configured directory does not exist, and we can't create it
issues.add(
getContext().createConfigIssue(
Groups.ROT13.name(), "directory", Errors.ROT13_00, f.getParentFile().getPath()
)
);
} else if (!f.createNewFile()) {
// We can't create the dummy file
issues.add(
getContext().createConfigIssue(
Groups.ROT13.name(), "directory", Errors.ROT13_01, f.getPath()
)
);
} else {
f.delete();
}
} catch (SecurityException | IOException e) {
// We're not allowed to do whatever we're trying to do
LOG.error("Exception accessing directory", e);
issues.add(
getContext().createConfigIssue(
Groups.ROT13.name(), "directory", Errors.ROT13_02, getDirectory(), e.getMessage(), e
)
);
}
The process() method uses the incoming filename and the configured directory to initialize an OutputFileRef:
// Get existing file's details
String fileName = record.get("/fileInfo/filename").getValueAsString();
FileRef fileRef = record.get("/fileRef").getValueAsFileRef();
// Create a reference to an output file
OutputFileRef outputFileRef;
outputFileRef = new OutputFileRef(getDirectory(), fileName);
Now we create a writer for the OutputFileRef, get the incoming file’s input stream and transform the data. Note that we have to close the output writer before reading the output file’s metadata, so that we get the correct file size.
// Read from incoming FileRef, write to output file
File file = outputFileRef.getFile();
try (BufferedWriter bw = new BufferedWriter(new FileWriter(file));
InputStream is = fileRef.createInputStream(getContext(), InputStream.class)) {
BufferedReader br = new BufferedReader(new InputStreamReader(is));
// rot13 the data
int ch;
while ((ch = br.read()) != -1) {
bw.write(rot13(ch));
}
// Close the output file now so that metadata is accurate
bw.close();
// Replace existing fileRef & fileInfo
record.set("/fileRef", Field.create(outputFileRef));
record.set("/fileInfo", createFieldForMetadata(getFileMetadata(file)));
}
The createFieldForMetadata() and getFileMetadata() are utility functions based on the built-in FileRef implementations in SDC.
Since the processor is accessing the disk, we need to set up appropriate permissions in ${SDC_CONF}/sdc-security.policy:
grant codebase "file://${sdc.dist.dir}/user-libs/customfileref/-" {
// Read input files
permission java.io.FilePermission "/Users/pat/Downloads/shakespeare/-", "read";
// Write output files - note - there permissions do NOT allow the
// processor to create the /tmp/rot13 directory itself
permission java.io.FilePermission "/tmp/rot13", "read";
permission java.io.FilePermission "/tmp/rot13/-", "read,write,execute,delete";
// Read file metadata
permission java.lang.RuntimePermission "accessUserInformation";
};
Now that the record has new values for /fileRef and /fileInfo, we just write the record to the batchMaker as usual, and it will be passed on down the pipeline. Subsequent processors and destinations see the record just as if it were a standard Whole File record.
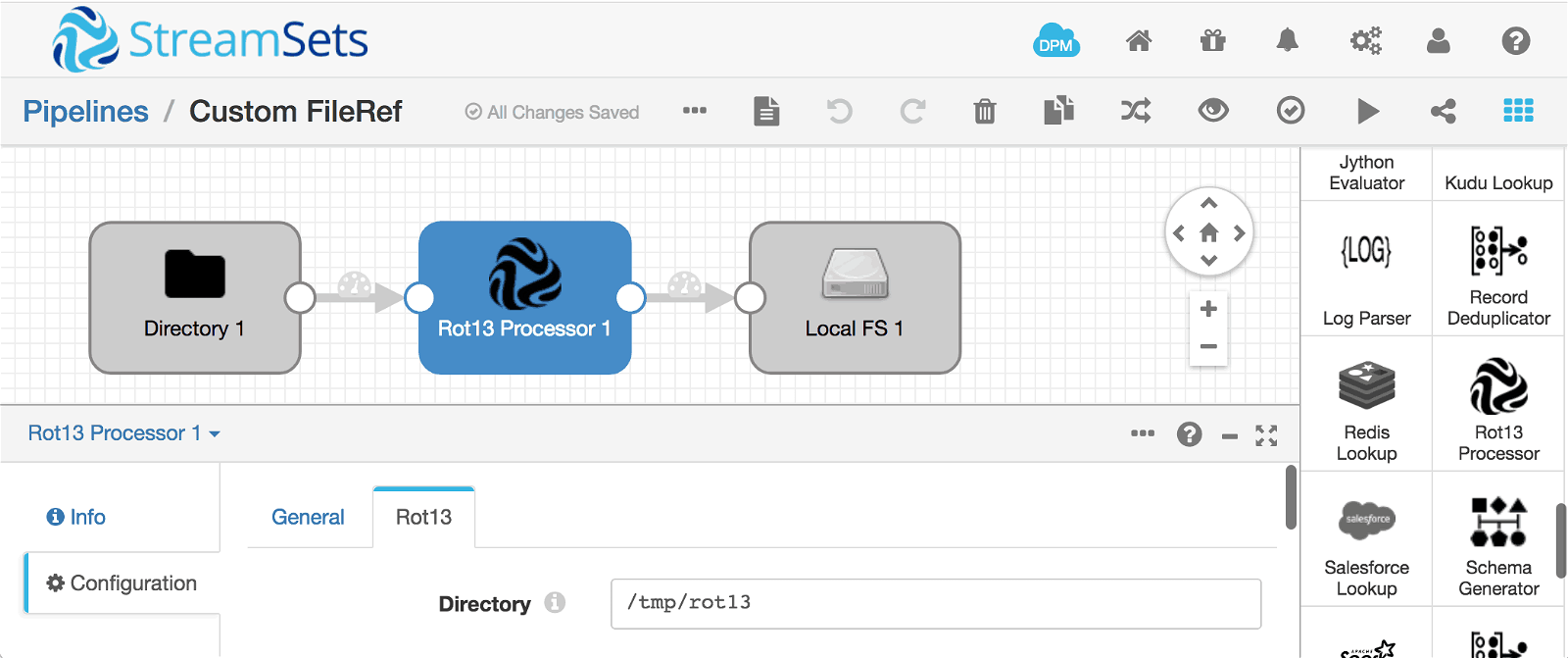 Running the pipeline on some handy input files results in the expected output files:
Running the pipeline on some handy input files results in the expected output files:
$ ls /tmp/out/2017-11-02-20
sdc-24e75fba-bd00-42fd-80c3-1f591e200ca6-comedies
sdc-24e75fba-bd00-42fd-80c3-1f591e200ca6-histories
sdc-24e75fba-bd00-42fd-80c3-1f591e200ca6-poems
sdc-24e75fba-bd00-42fd-80c3-1f591e200ca6-tragedies
Let’s take a look at some of the file content:
$ head /tmp/out/2017-11-02-20/sdc-24e75fba-bd00-42fd-80c3-1f591e200ca6-comedies
NYY'F JRYY GUNG RAQF JRYY
QENZNGVF CREFBANR
XVAT BS SENAPR (XVAT:)
Pretty unintelligible! Fortunately, there’s a handy shell command that can rot13 the data back to its original state:
$ head /tmp/out/2017-11-02-20/sdc-24e75fba-bd00-42fd-80c3-1f591e200ca6-comedies | tr '[A-Za-z]' '[N-ZA-Mn-za-m]'
ALL'S WELL THAT ENDS WELL
DRAMATIS PERSONAE
KING OF FRANCE (KING:)
All is, indeed, well that ends well!
Note – the output files are left in place in the configured directory, so you’ll need to clean them up periodically:
$ ls /tmp/rot13
comedies histories poems tragedies
Conclusion
StreamSets Data Collector’s Whole Files data format allows you to build pipelines that read files unparsed from a variety of origins – Amazon S3, Directory, SFTP/FTP Client and, soon, Google Cloud Storage. Script Evaluators can access Whole File content via the FileRef field’s createInputStream method; custom processors written in Java can both read incoming and write outgoing Whole File data to Amazon S3, Azure Data Lake Store, Hadoop FS, Local FS, MapR FS and, again soon, Google Cloud Storage.
What use cases do you have for processing Whole File data? Let us know in the comments!