Do you need to transform data? Good new is that I’ve written quite a bit over the past few months about the more advanced aspects of data manipulation in StreamSets Data Collector Engine (SDC) – writing custom processors, calling Java libraries from JavaScript, Groovy & Python, and even using Java and Scala with the Spark Evaluator. As a developer, it’s always great fun to break out the editor and get to work, but we should be careful not to jump the gun. Just because you can solve a problem with code, doesn’t mean you should. Using SDC’s built-in processor stages is not only easier than writing code, it typically results in better performance. In this blog entry, I’ll look at some of these stages, and the problems you can solve with them.
I’ve created a sample pipeline showing an extended use case using the Dev Raw Data origin and Trash destination so it will run no matter your configuration. Run preview, and you’ll see exactly what’s going on. Experiment with the configuration and sample data to see how you can apply the same techniques to transform data in your business.
We’ll start with some company data in JSON format such as you might receive from an API call and proceed through a series of transformations resulting in records that are ready to be inserted in a database.
Transform Data with Pre-Built Processors
Field Pivoter
The Field Pivoter can transform data by splitung one record into many, ‘pivoting’ on a collection field – that is, a list, map, or list-map. This is particularly useful when processing API responses, which frequently contain an array of results.
For example, let’s say we have the following input:
{
"status": 0,
"results": [
{
"name": "StreamSets",
"address" : {
"street": "2 Bryant St",
"city": "San Francisco",
"state": "CA",
"zip": "94105"
},
"phone": "(415) 851-1018"
},
{
"name": "Salesforce",
"address" : {
"street": "1 Market St",
"city": "San Francisco",
"state": "CA",
"zip": "94105"
},
"phone": "(415) 901-7000"
}
]
}
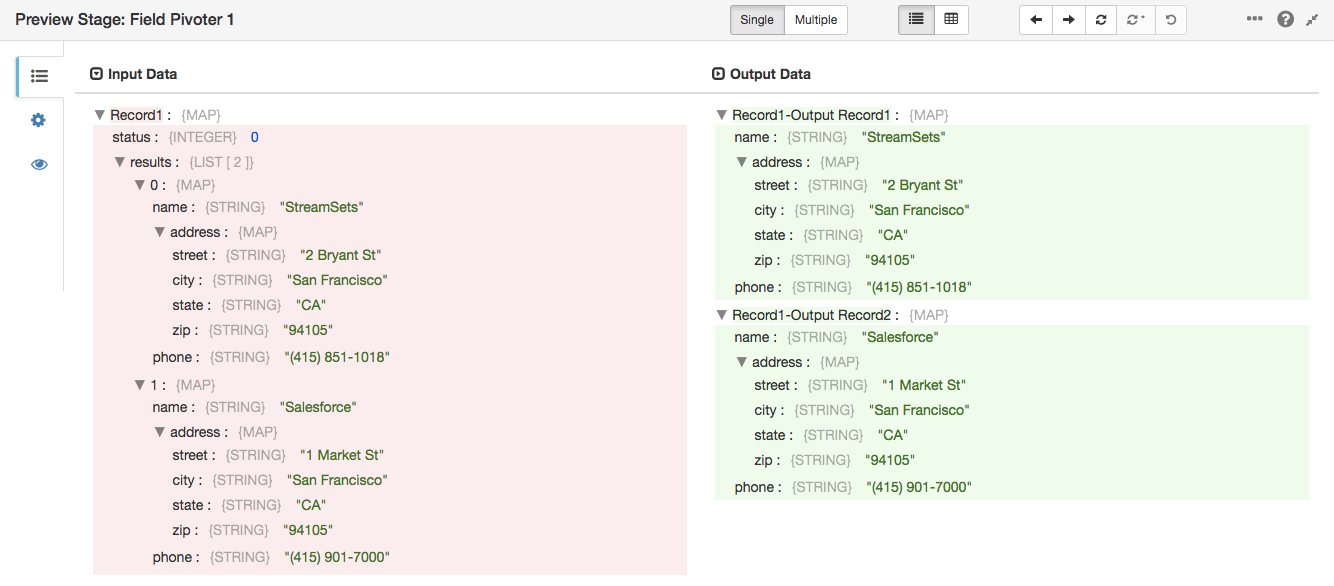
We want to create a record for each result, with name, street, etc as fields. Configure a Field Pivoter to pivot on the /results field and copy all of its fields to the root of the new record, /

Let’s take a look in preview:
Field Flattener
Data formats such as Avro and JSON can represent hierarchical structures, where records contain fields that are themselves collections of other fields. For example, each record in our use case now has the following structure:
{
"name": "StreamSets",
"address": {
"street": "2 Bryant St",
"city": "San Francisco",
"state": "CA",
"zip": "94105"
},
"phone": "(415) 851-1018"
}
Many destinations, such as relational databases, however, require a ‘flat’ record, where each field is simply a string, integer, etc. The Field Flattener transforms data, as its name implies, by flattening the structure of the record. Configuration is straightforward – specify whether you want to flatten the entire record, or just a specific field, and the separator you would like to use. For example:

Applying this to the sample data above results in a record with fields address.street, address.city, etc:

Field Renamer
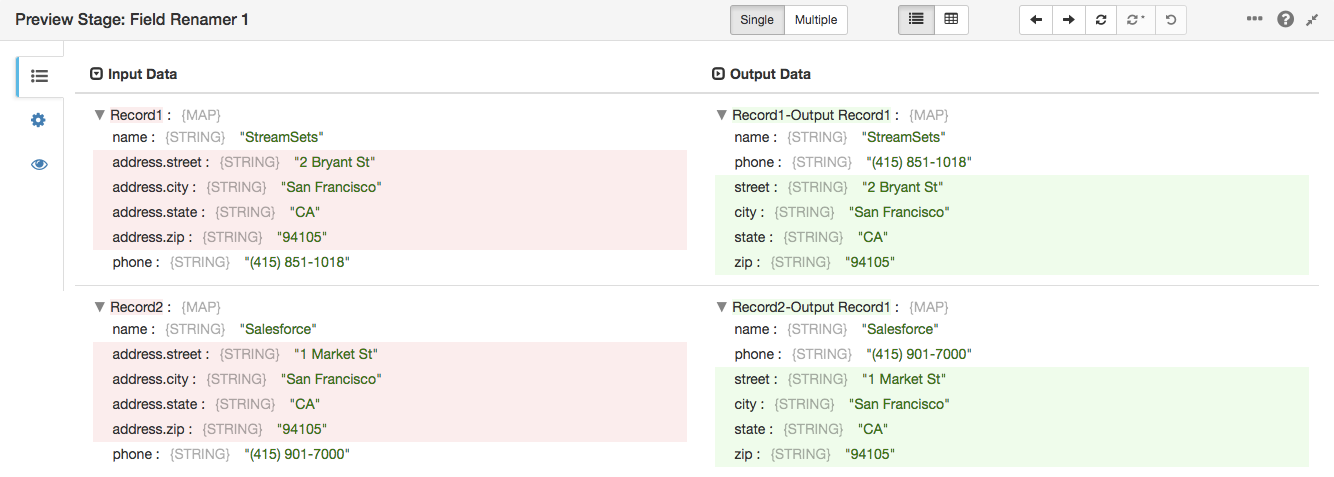
So we’ve got a nice flat record structure, but those field names don’t match the columns in the database. It would be nice to rename those fields to street, city, etc. The Field Renamer has you covered here and is ready to simply plugin to your pipeline to transform data. Now, you could explicitly specify each field in the address, but that’s a bit laborious, not to mention brittle in the face of data drift. We want to be able to handle new fields, such as latitude and longitude, appearing in the input data without having to stop the pipeline, reconfigure it, and restart it. Let’s specify a regular expression to match field names with the prefix address.

That regular expression – /'address\.(.*)' – is a little complex, so let’s unpack it. The initial / is the field path – we want to match fields in the root of the record. We quote the field name since it contains what, for SDC, is a special character – a period. We include that period in the prefix that we want to match, escaping it with a backslash, since the period has a special meaning in regular expressions. Finally, we use parentheses to delimit the group of characters that we want to capture for the new field name: every remaining character in the existing name.
The target field expression specifies the new name for the field – a slash (its path), followed by whatever was in the delimited group. This was all a precise, if slightly roundabout, way to say “Look for fields that start with address. and rename them with whatever is after that prefix.
Let’s see it in action on the output from the Field Flattener:

StreamSets enables data engineers to build end-to-end smart data pipelines. Spend your time building, enabling and innovating instead of maintaining, rewriting and fixing.
Field Splitter
Our (imaginary!) destination needs street number separately from street name. No problem! The Field Splitter was designed for exactly this situation. It works in a similar way to the renamer, but on field values rather than names.
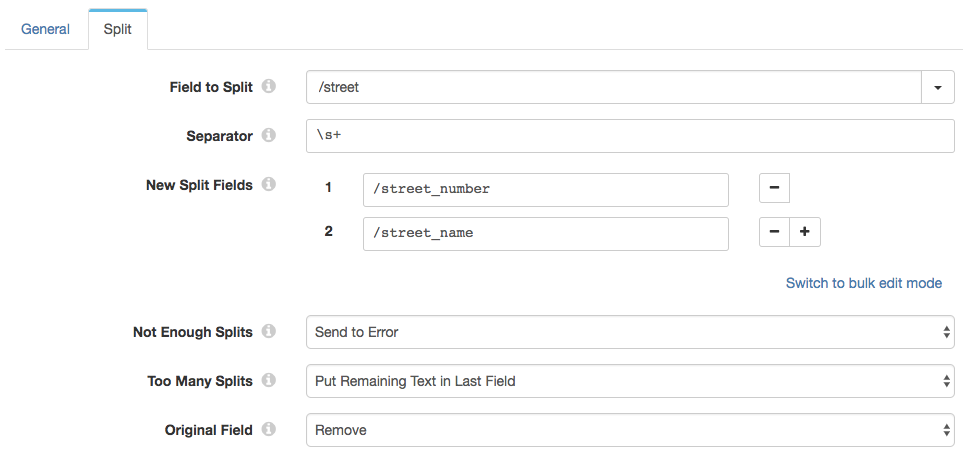
We’re splitting the /street field on sequences of one or more whitespace characters. This will ensure that 2 Bryant St (with two spaces) will be treated the same as 2 Bryant St (with a single space). We put the results of the split operation into two new fields: /street_number and /street_name. If we can’t split the /street field in two, then we send the record to the error stream; if there are more than two results, we want to put the remaining text, for example, Bryant St in the last field. Finally, we want to remove the original /street field.
The results are as you might expect:

Your Pipeline to Transform Data
Here is the final pipeline, that pivots, flattens, renames and splits fields in the incoming data:

I mentioned performance earlier. As a quick, albeit unscientific, test, I ran this pipeline on my MacBook Air for a minute or so; it processed about 512 records/second. I coded up the same functionality in Groovy, ran it for a similar length of time, and it only processed about 436 records/second.
Deploy StreamSets Data Collector Engine in your choice of cloud platform, import the field manipulation pipeline, and try it out.