
Hari Nayak’s recent blog post provides a quickstart for using StreamSets Control Hub to deploy multiple instances of StreamSets Data Collector on Google’s Kubernetes Engine (GKE). This post modifies the core scripts from that project in order to run on Minikube rather than GKE. As Minikube can run on a laptop, this allows lightweight testing of Control Hub’s Kubernetes support without needing to use a cloud-based Kubernetes cluster.
Consider a StreamSets pipeline like the one below that consumes messages from a Kafka topic, performs transformations using a JDBC Lookup Processor and an Expression Evaluator and then updates an Elasticsearch index:

If the Kafka topic the pipeline consumes messages from has a large number of partitions and a high rate of writes, there can be pressure to scale the number of concurrent Kafka consumers. StreamSets’ Kafka Multitopic Consumer allows multiple threads to be specified, providing a mechanism to scale up within a single instance of StreamSets Data Collector. To scale out processing, the pipeline could be deployed across a set of statically deployed Data Collector instances created in advance, or onto a set of Data Collector instances dynamically deployed by Control Hub onto a Kubernetes cluster.
The sections below show how to deploy multiple instances of Data Collector each running a copy of this pipeline on Minikube.
Prerequisites
- A StreamSets Control Hub account with Auth Token Administrator and Provisioning Operator roles. (Apply for a Control Hub trial account here)
- A configured Authoring Data Collector (this will already be setup if you are using StreamSets’ hosted Control Hub)
- kubectl – the Kubernetes command-line tool
- jq – a command-line tool for manipulating JSON
- An existing Minikube installation
- A Docker ID and Docker Repo if you wish to publish your own custom Data Collector images
I am running Minikube v0.25.0 on MacOS with the VirtualBox driver
Preconfigure a Data Collector Docker Image with the required Stage and External Libraries
To run the sample pipeline described above, Data Collectors will need to have Kafka, JDBC and Elasticsearch stage libraries pre-installed as well as the MySQL JDBC Driver external library.
Please see the example here that describes how a pre-configured Data Collector image can be published to a Docker repo.
We’ll specify that custom image in Control Hub when deploying Data Collectors using Kubernetes in the steps below.
Deploy the Control Agent into Minikube
The Control Agent (also known as a Provisioning Agent) is a containerized application that runs in a container orchestration framework in your environment. The agent communicates with Control Hub to automatically provision Data Collector containers. Here is how to deploy the Control Agent on Minikube:
- Start the Minikube cluster if it is not yet running:
$ minikube start
- Clone or download this project to your local machine and then switch to the project’s k8s-minikube directory
- Run the project’s startup.sh script by executing a command of this form (all on one line):
$ SCH_ORG=<org> SCH_USER=<user>@<org> SCH_PASSWORD=<password> KUBE_NAMESPACE=<your_namespace> [SCH_URL=<SCH_URL>] ./startup.sh
Where:
- SCH_ORG is the name of the Organization you have been assigned in cloud.streamsets.com or your own standalone instance of StreamSets Control Hub
- SCH_USER and SCH_PASSWORD are your credentials in cloud.streamsets.com or StreamSets Control Hub
- KUBE_NAMESPACE is the Kubernetes namespace you wish to use
- The default value for SCH_URL is “https://cloud.streamsets.com” so you can omit that argument if you are using that URL, or provide a value if you have your own Control Hub instance
Make sure the SCH_USER specified has Auth Token Administrator and Provisioning Operator roles in cloud.streamsets.com or your local StreamSets Control Hub as appropriate.
An example command looks like this:
$ SCH_ORG=globex SCH_USER=mark@globex SCH_PASSWORD=password123 KUBE_NAMESPACE=streamsets ./startup.sh
If all goes well you should see a message like this on the console:
DPM Agent “375F7E88-A7C6-4D6A-B49A-DD53CBF311C7” successfully registered with SCH
Within StreamSets Control Hub, you should see a Provisioning Agent in a healthy state like this:
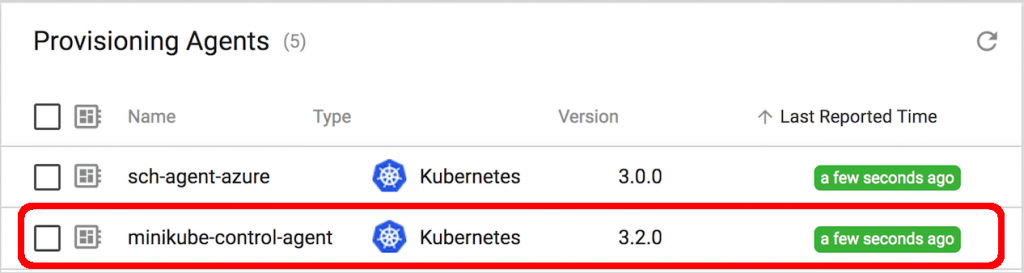
Create a Deployment
A deployment is a logical grouping of Data Collector containers deployed by a Provisioning Agent to a container orchestration framework. All Data Collector containers in a deployment are identical and highly available.
Our newly registered Provisioning Agent can now be used to deploy a set of Data Collectors onto the Minikube cluster. To do that, add a new Deployment, set the Provisioning Agent to the “minikube-control-agent”, set a number of instances (I’ll use 2 in this example) and set one or more labels to identify the Data Collectors deployed in Minikube:
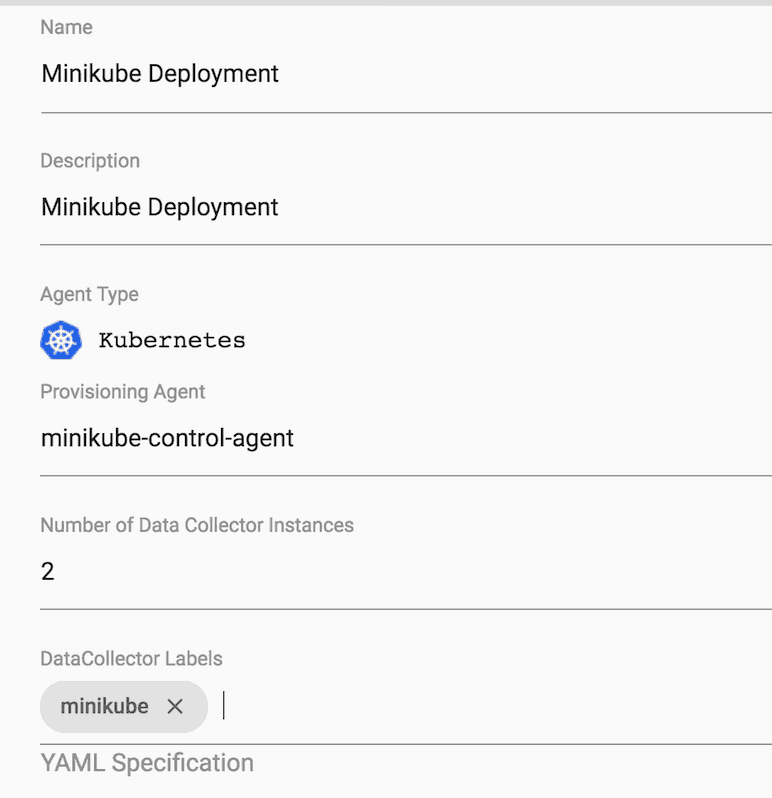
Continue scrolling down in the Add Deployment dialog and edit the yaml to set your own custom image for the Data Collector deployment. The setting below points to the custom Data Collector Docker image I published earlier:
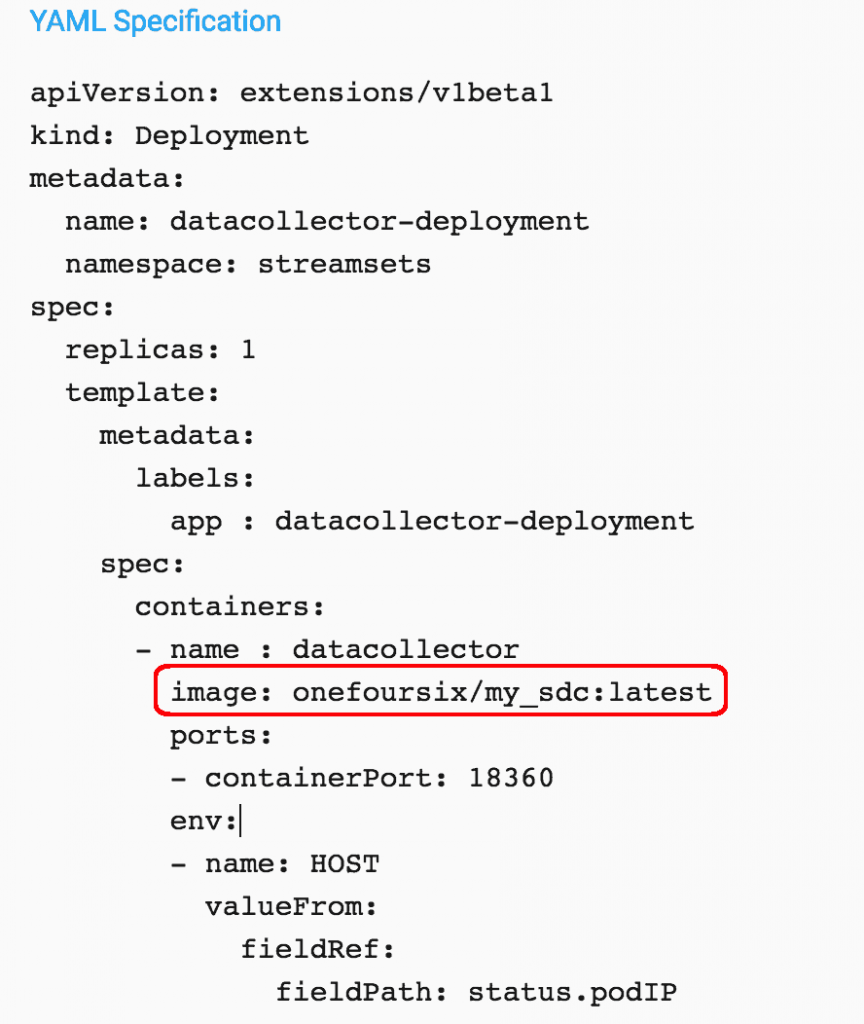
Save and start the Deployment. The Deployment will transition to an Active state once the new Data Collectors are online:
![]()
View the newly deployed Data Collectors
Refresh the Data Collector list, toggle the setting to “View Labels” and you should see the new Data Collectors with the specified labels:
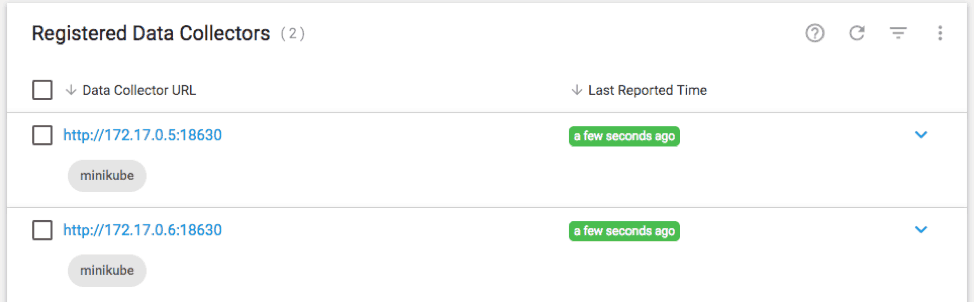
Create a Job
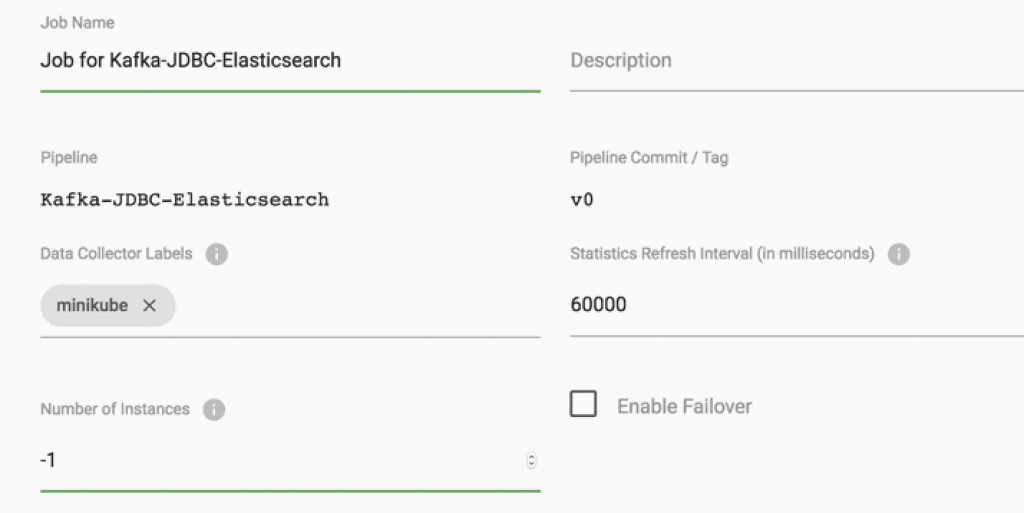
Create a Job for the Kafka-JDBC-Elasticsearch pipeline specifying the “minikube” label to pin the job to the Minikube-based Data Collectors and “-1” instances so the Job will run on all Data Collectors that match the minikube label (in my case two):
Start the job
Start the job and make sure it becomes Active and is running on both Data Collectors in Minikube:

View aggregate metrics for the job:

Conclusion
This blog post shows how easy it is to automatically deploy custom Data Collector images and Pipelines onto a Minikube-based Kubernetes environment using StreamSets Control Hub. Give it a try!