A major challenge when deploying data pipelines to run on Kubernetes is how to handle Kerberos principals and Kerberos keytabs needed when pipelines write to secure Hadoop.
What Are Kerberos Principals?
Kerberos principals are identifiers that represent either users or service daemons. User principals are often constructed as name@realm and are not bound to a specific host. Principles for service daemons are typically of the form name/host@realm.
What Is A Kerberos Keytab?
Kerberos keytabs are files that associate encrypted keys with principals and serve as a basis for authentication.
The use of Kerberos keytabs for principals of the form name@realm (without a host field), incurs security risks as a Kerberos keytab for such a principal could be used on any host in the enterprise. Best practice for Kerberos principals is that they be of the form name/host@realm.
But how can host-qualified principals and keytabs be automatically generated for Kubernetes-based deployments, which can be dynamic, ephemeral and auto-scaling, with host names not necessarily known beforehand? The answer to that question is: StreamSets Provisioning Agent!
The below image depicts multiple StreamSets Data Collector Engine deployments, each with a different Kerberos user and kerberos keytab associated with them.
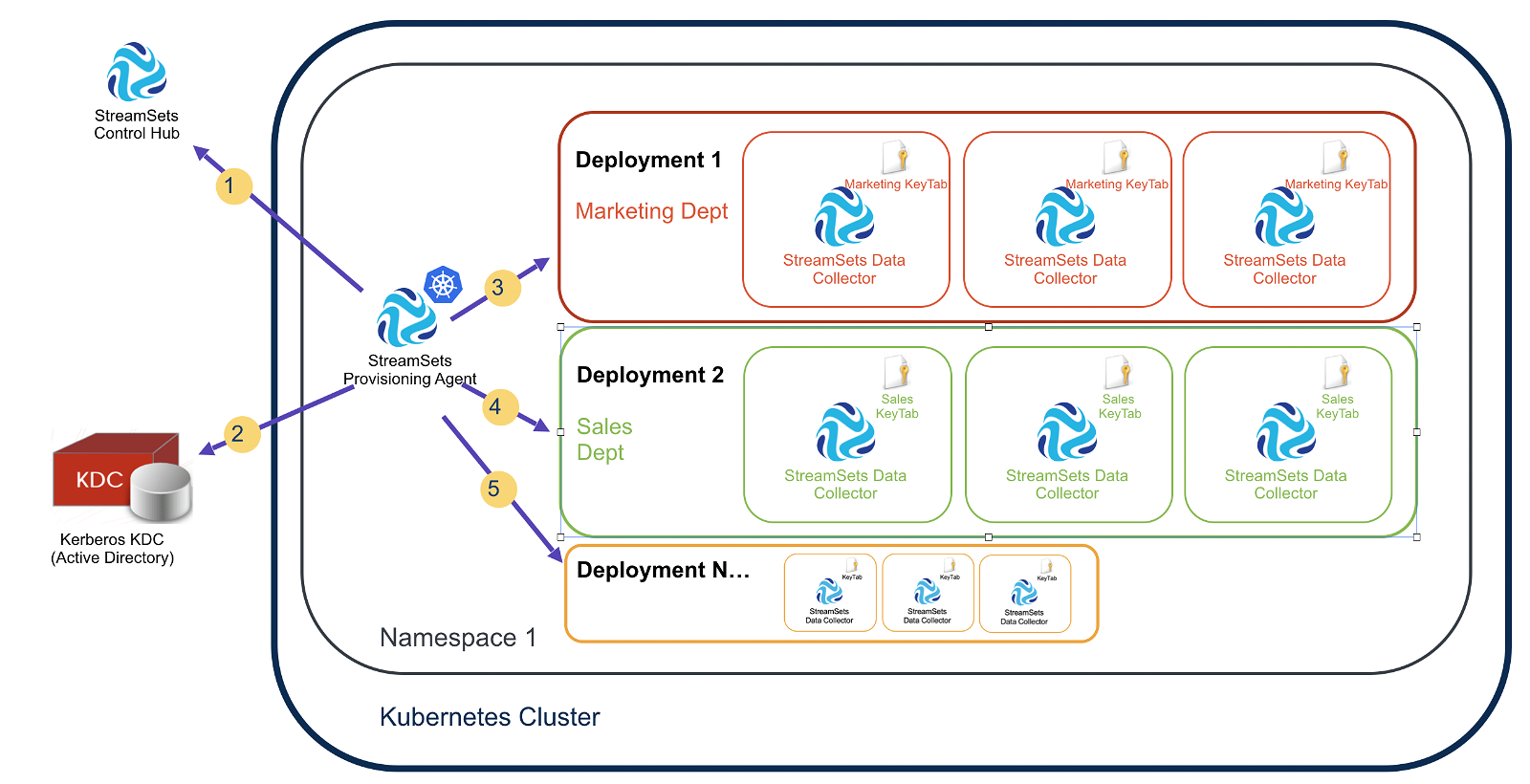
Here is how the StreamSets Provisioning Agent, in conjunction with StreamSets Control Hub, automates the Kerberos aspects of the deployment process:
Step 1: The Provisioning Agent polls Control Hub looking for tasks to perform.
Step 2: When there is a deployment request (for example, “create two Data Collectors for the Marketing Department with the Kerberos user ‘marketing'”), the Provisioning Agent interacts with the Kerberos KDC and creates Kerberos principals of the form marketing/@ and generates keytabs for those principals.
Step 3: The Provisioning Agent injects the Kerberos principal name and keytab into each Data Collector’s configuration.
Step 4: Multiple deployments can have unique principals associated with their own set of Data Collectors.
Step 5: The Provisioning Agent will dynamically provision new Kerberos principal names and a kerberos keytab or multiple when needed to respond to horizontal pod autoscaling events. For example, if a third Data Collector is spawned for a given deployment under load, the new Data Collector will automatically get the kerberos credentials it needs, tied to the new host.
An additional service performed by the Provisioning Agent is the automatic cleanup of the KDC when Kubernetes deployments terminate or pods are bounced. This prevents the KDC from being littered with no-longer needed principals.
Provisioning Agent Configuration
In the Provisioning Agent Helm Chart (aka “Control Agents”), specify Kerberos configuration in the Chart’s values.yaml file as follow:
krb: enabled: false encryptionTypes: containerDn: ldapUrl: adminPrincipal: adminKey: realm: kdcType: < AD | MIT >
With such configuration a Provisioning Agent will be able to interact with a Kerberos KDC.
Note: All credentials and Kerberos configuration details provided in the Chart are managed as Kubernetes Secrets.

StreamSets enables data engineers to build end-to-end smart data pipelines. Spend your time building, enabling and innovating instead of maintaining, rewriting and fixing.
Creating a Deployment with a given Kerberos Principal
Once a Kerberos-enabled Provisioning Agent has been deployed, one can easily create a Kubernetes-based deployment of Data Collectors associated with a given Kerberos user. Here is an example of creating such a Deployment using Control Hub:
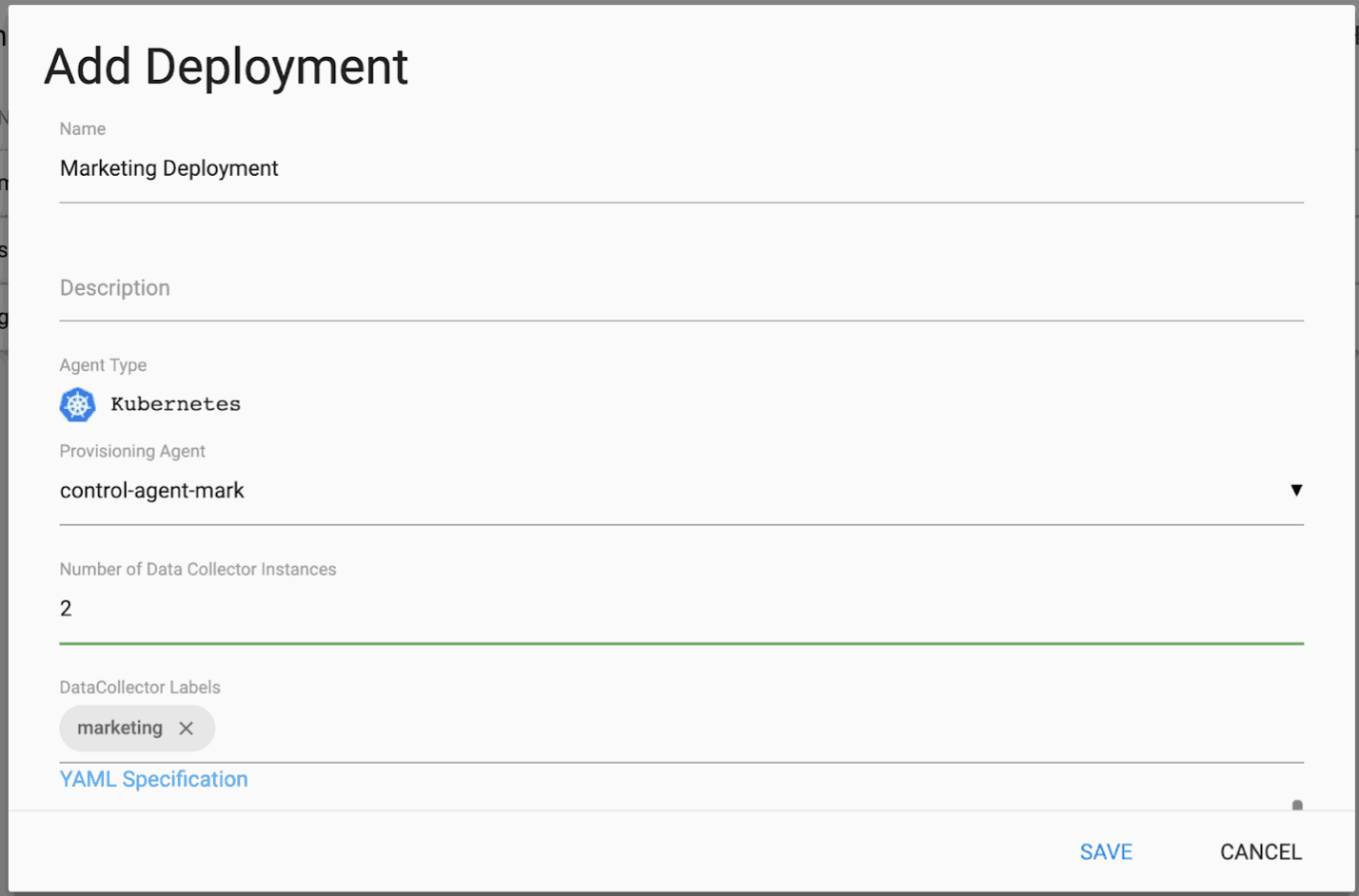
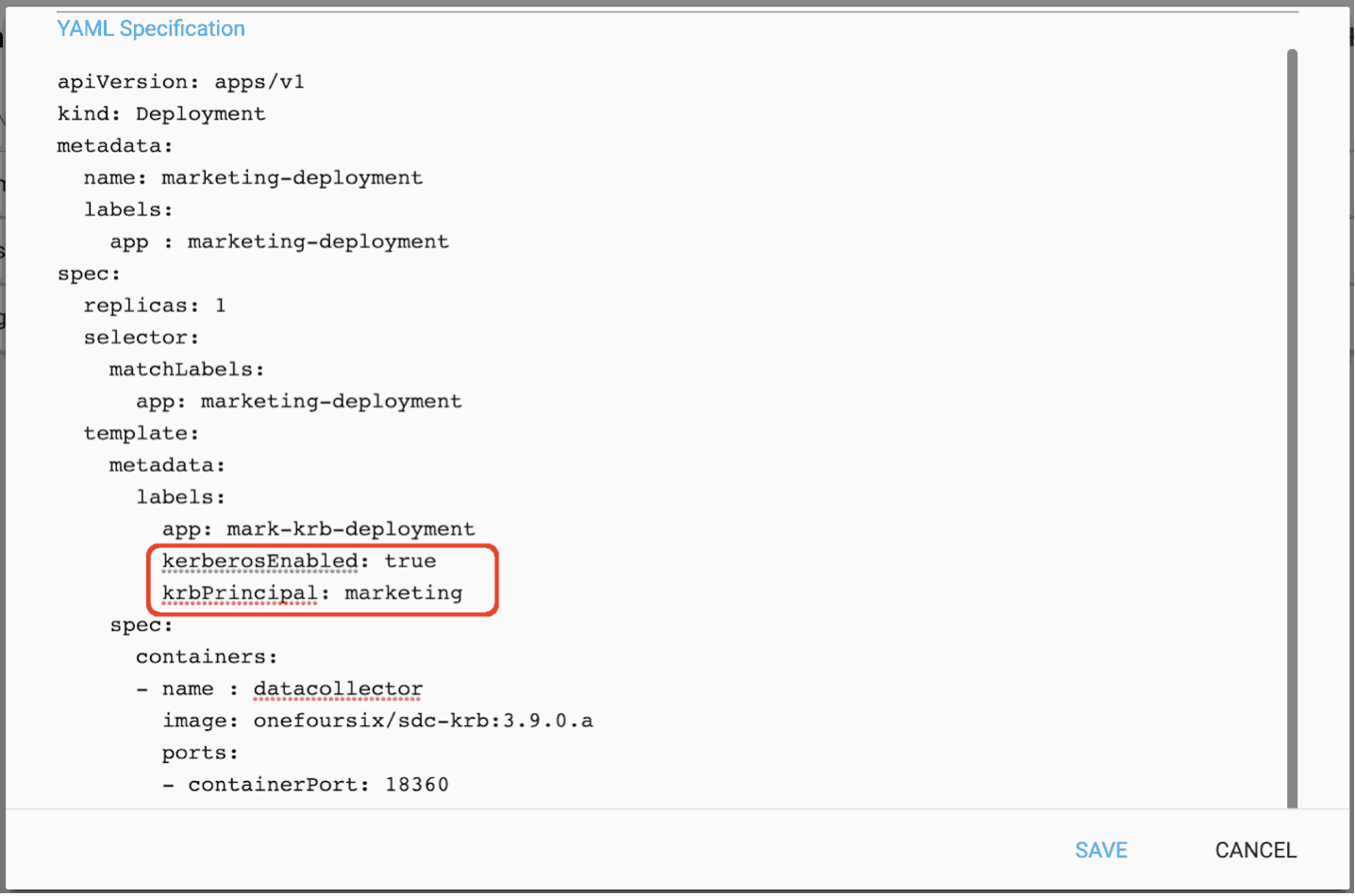
The Deployment is for the Marketing Department and specifies two StreamSets Data Collectors, a fast data ingestion engine. (See the next page for the YAML Specification.) In the YAML Specification for the Marketing Department Deployment, the use of Kerberos is enabled and the Kerberos user “marketing” is specified as shown below:
The Marketing Deployment is activated in Control Hub as show below:

To see the two “marketing” pods, run the following command:
$ kubectl get pods
That should output something similar to:
NAME READY STATUS RESTARTS AGE control-agent-6775c99c65-92thr 1/1 Running 0 14h marketing-deployment-7bb75898dd-5kxql 1/1 Running 0 91s marketing-deployment-7bb75898dd-kxcx7 1/1 Running 0 91s
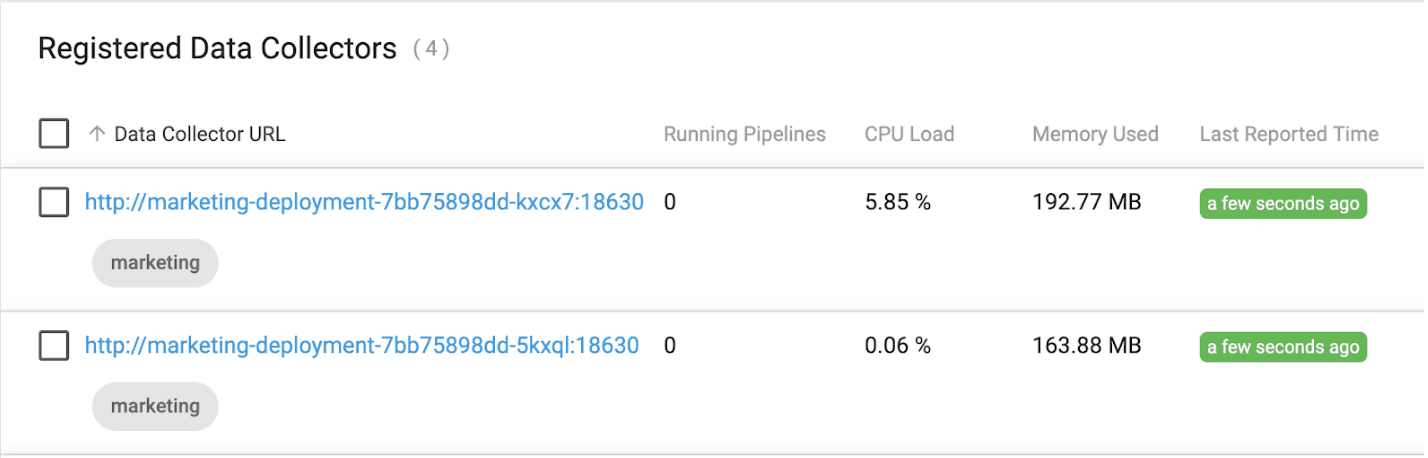
After a minute or so, the two new Data Collectors will have registered with Control Hub and can be seen tagged with the “marketing” label as shown below:
We can also see two Kerberos principals were created for the marketing user tied to the specific hosts:
kadmin.local: listprincs ... marketing/10.60.1.25@ONEFOURSIX marketing/10.60.1.26@ONEFOURSIX
Note the Kerberos configuration injected into a Data Collectors config like this:
$ kubectl exec -it marketing-deployment-7bb75898dd-5kxql bash bash-4.4# grep kerberos /etc/sdc/sdc.properties kerberos.client.keytab=sdc.keytab kerberos.client.enabled=true kerberos.client.principal=marketing/10.60.0.16@ONEFOURSIX
Scaling Up a Deployment
We can scale up a deployment using Control Hub. For example, scaling up from 2 to 3 instances as shown below:
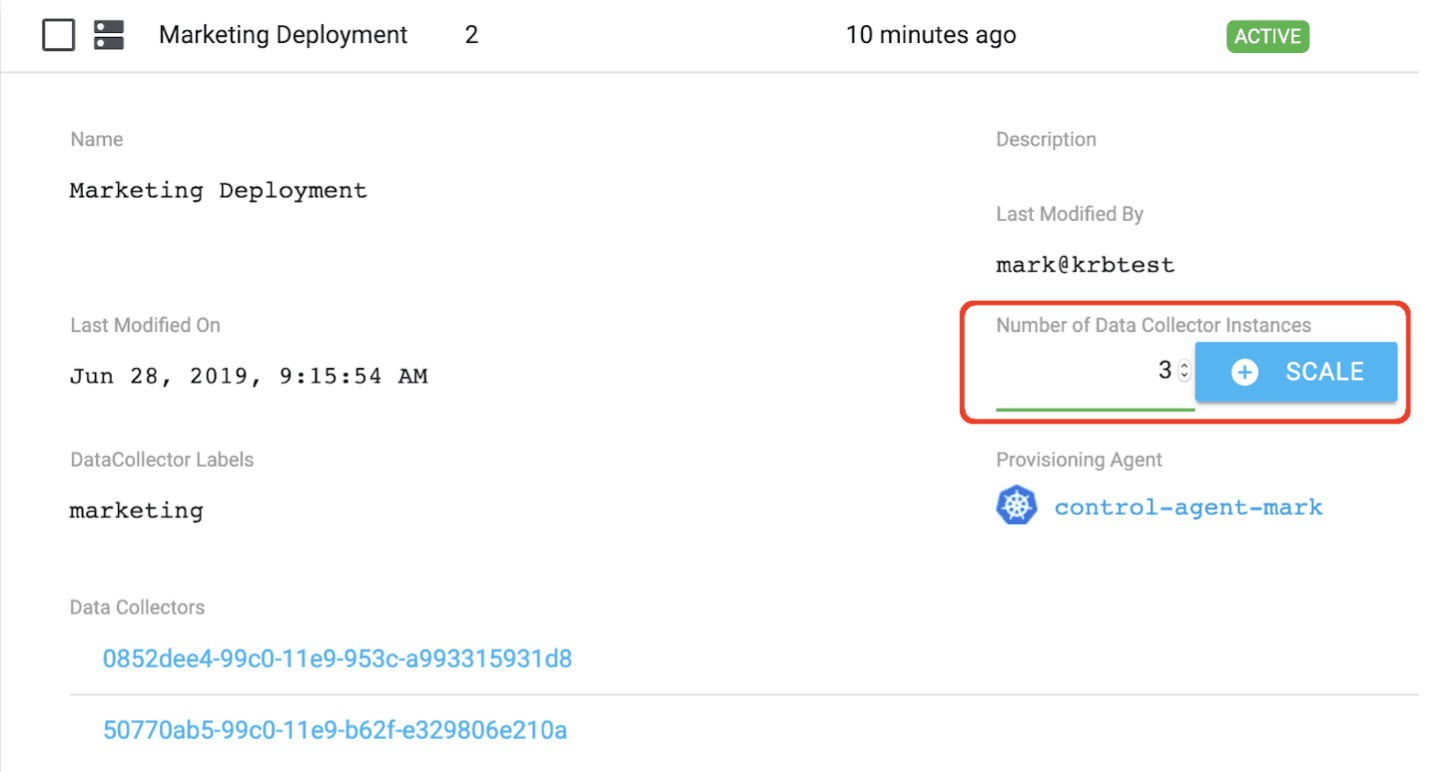
Clicking the highlighted SCALE button results in a third Data Collector pod being deployed as shown below:
$ kubectl get pods NAME READY STATUS RESTARTS AGE control-agent-6775c99c65-92thr 1/1 Running 0 14h marketing-deployment-7bb75898dd-5kxql 1/1 Running 1 18m marketing-deployment-7bb75898dd-kxcx7 1/1 Running 0 18m marketing-deployment-7bb75898dd-qld7w 1/1 Running 0 66s
The new Data Collector registers with Control Hub when it comes online as shown below:
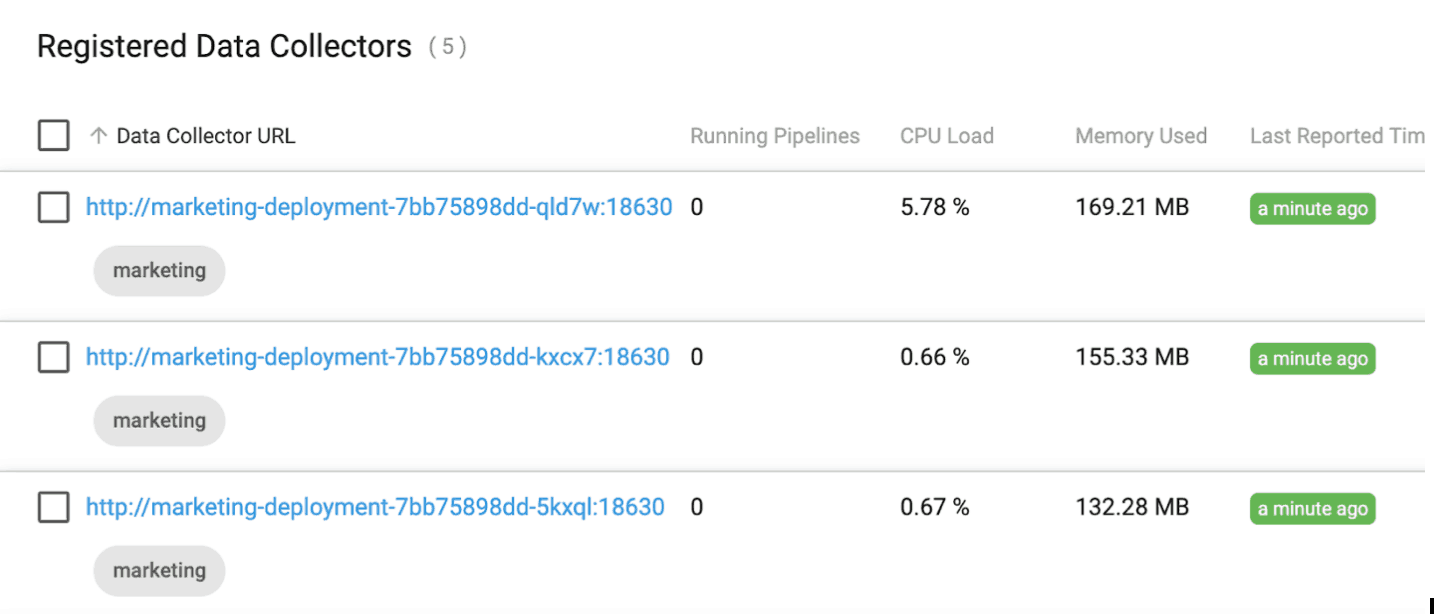
We can confirm a third Kerberos principal was created by running the following command:
kadmin.local: listprincs ... marketing/10.60.0.15@ONEFOURSIX marketing/10.60.1.25@ONEFOURSIX marketing/10.60.1.26@ONEFOURSIX
If we delete one of the pods and allow Kubernetes to spin up a new one, we can see the Provisioning Agent deleted the no longer needed principal and added the new principal. Note the host changed from 10.60.1.25 to 10.60.0.16.
kadmin.local: listprincs ... marketing/10.60.0.15@ONEFOURSIX marketing/10.60.0.16@ONEFOURSIX marketing/10.60.1.26@ONEFOURSIX
When the deployment is deleted, all of the “marketing” principals are deleted from the KDC as well.
Summary of Kerberos Keytab Automation
In this blog post, you learned how easy it is to create, manage and scale your StreamSets Data Collector Engine deployments on Kubernetes using StreamSets Provisioning Agent in StreamSets Control Hub. If you’re interested in learning how to scale StreamSets Data Collectors on Azure Kubernetes Service, check out this blog post.