Given the exponential growth of data rates and the time-critical demand for responses, we must consider robust approaches to analyze and deliver predictions, inferences, and/or binary classification or other in near real-time.
Over the past decade, digital transformation has evolved such that every system and device has a digital trail: from IT servers to factory equipment to consumer electronics to buildings to cars. Increasing data volumes, rates, and variety have created increasing complexity, not to mention these new datasets must be analyzed in real-time. Fit-for-purpose data platforms allow for storing and applying advanced analytics to unlimited raw data. Analytics can occur on edge systems, in data centers, or across cloud providers. Streaming compute platforms enable the processing of real-time data.
Streaming Data Ingest for Real-time Streaming / Binary Classification
The StreamSets DataOps Platform enables companies to build, execute, operate, and protect continuous dataflows that unleash pervasive analytics. It combines award-winning software featuring smart data pipelines with a cloud-native control plane that helps enterprises manage their data movement as a continuous ingestion practice.
To provide time-critical responses for analyzing data sets, StreamSets provides the capability to create pipelines that ingest datasets or dimensions and generate predictions or classifications within a contained environment. All this without having to initiate HTTP or REST API calls to ML models served and exposed as web services. For example, StreamSets pipelines can now detect fraudulent transactions or perform natural language processing on text in real-time as data is passing through various stages before being stored in the final destination—for further processing or decision making.
Consider the use case of classifying a breast cancer tumor as being malignant or benign. The (Wisconsin) breast cancer is a classic dataset and is available as part of scikit-learn.
Note: Learn more about how to train and export a TensorFlow model using this dataset.
How to Use TensorFlow Classification in a Streaming Data Pipeline
Once the model is trained and exported using TensorFlow SavedModelBuilder, using it in your StreamSets streaming pipelines for prediction or binary classification or other is pretty straightforward. Upon previewing (or executing) the pipeline, the input breast cancer records are passed through the pipeline stages including the TensorFlow model:
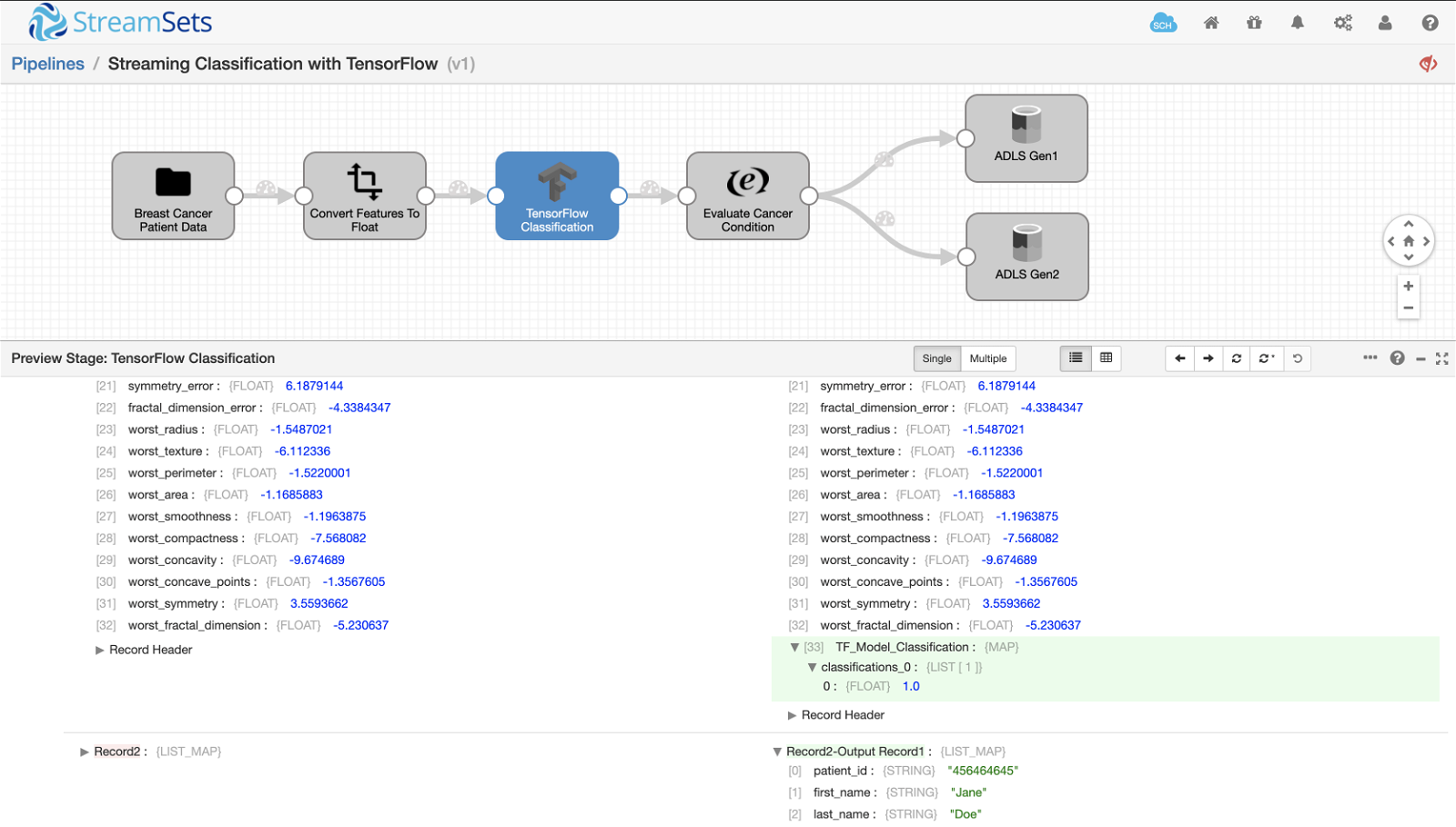
The final output records are sent to both Azure Data Lake Storage Gen1 and Azure Data Lake Storage Gen2 as shown above. The output includes breast cancer features used by the model for binary classification, model output value of 0 or 1 in user-defined field TF_Model_Classification, and respective cancer condition Benign or Malignant in field Condition created by Expression Evaluator.
Go to the details on data preparation stages for TensorFlow and Kafka pipeline.
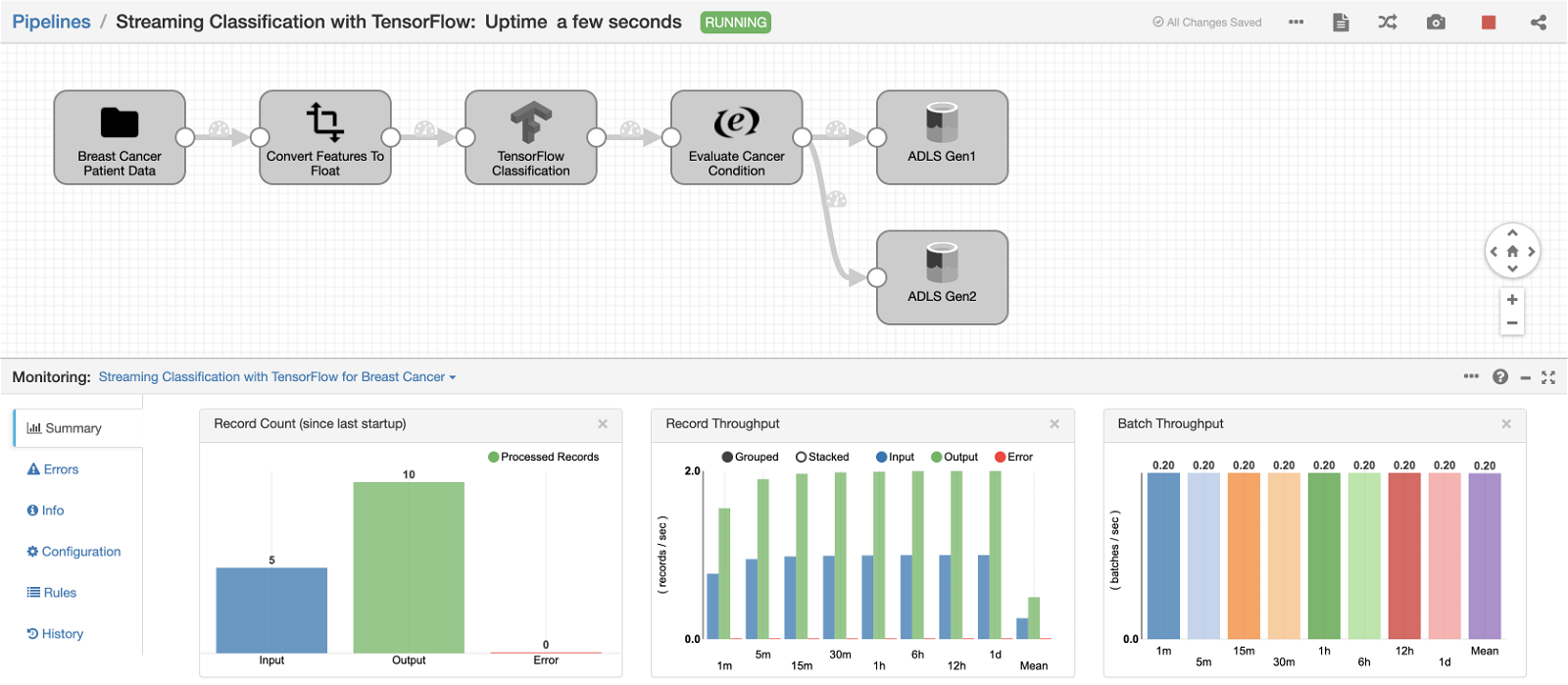
Here’s a screenshot of the pipeline continuously reading patient data and classifying breast cancer tumor as being Benign or Malignant in real-time:
Demo Video
Summary
The example above illustrates the use of Machine Learning Evaluators in StreamSets. These evaluators will enable you to discover useful information in streaming data with pre-trained ML models. Generating predictions and/or binary classification or other without having to write any custom code becomes extremely easy and at the same time provides time critical responses for analyzing streaming data sets.
