The benefits of data warehouses are numerous and they have become essential for organizations dealing with massive amounts of data, and while other alternatives come to market their adoption remains on the rise. This increased adoption accounts for a projected Compound Annual Growth Rate (CAGR) of 10.7% from 2020 to over $51B in 2028. The growth rate comes as no surprise, as there is increased demand for a dedicated storage system to handle business analytics at scale with low latency.
Organizations must design a warehouse architecture that fits their data needs while maintaining standard best practices to harness the full potential of data warehouses. Businesses may choose to adopt a cloud data warehouse, a service provided by cloud providers, or host their data warehouses on-premise. Each approach has its control, scalability, and maintenance trade-offs.
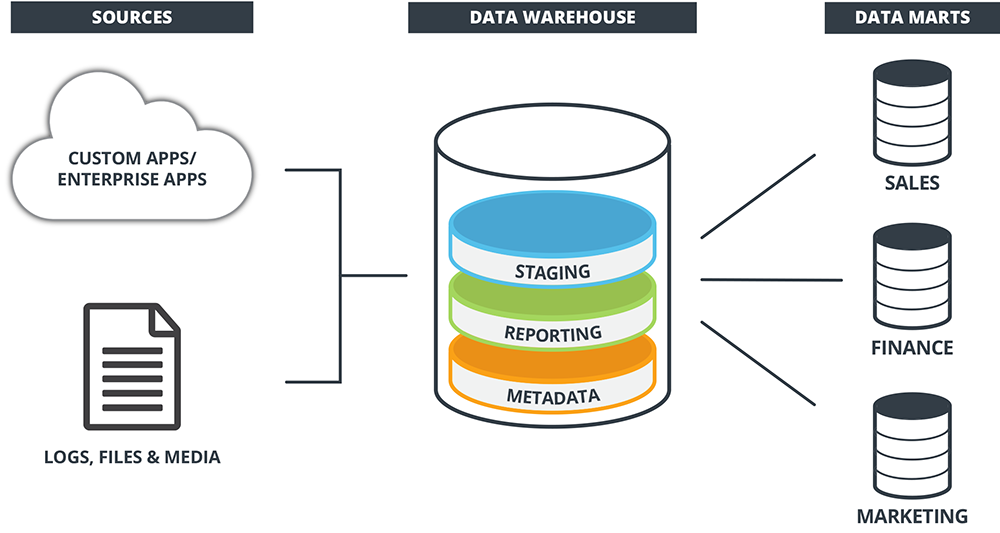
Data warehouses usually consist of data warehouse databases; Extract, transform, load (ETL) tools; metadata, and data warehouse access tools. These components may exist as one layer, as seen in a single-tiered architecture, or separated into various layers, as seen in two-tiered and three-tiered architecture.
Let’s explore data warehouse architecture and best practices when designing a data warehouse solution.
- The Components of Data Warehouse Architecture
- Data Warehouse Architecture Layers
- Best Practices for Data Warehouse Architecture
- Principles of Data Warehouse Architecture
- Data Marts: Customized Mini Data Warehouses
- Architecture differences between cloud and on-premise data warehouses
- Data Warehouses vs. Data Lakes vs. Data Lakehouses
- Conclusion
The 4 Components of Data Warehouse Architecture
Data warehouses consist of four essential components:
- Data warehouse database: This is a crucial component of the warehouse architecture and refers to the database that houses all business data.
- ETL or ELT tools: These tools help transform the data into a single format either on or off of the data warehouse. ETL refers to the transformation of data away from the data warehouse. When it is done on the data warehouse it is referred to as ELT.
- Data warehouse metadata: Metadata refers to information about data stored in the data warehouse. It contains tables, schemas, and data origin, among others.
- Data warehouse access tools: This is usually the last component of enterprise data warehouse architecture and allows users to interact with the data warehouse. Data warehouse access tools may include query, reporting, data mining, and Online Analytical Processing(OLAP) tools.
The Layers of a Data Warehouse
Data warehouse design can be complex, as the data warehouse must possess the ability to integrate several data sources and store massive volumes of data while operating at low latency and high performance. Applying layers to warehouse architecture plays a huge role in improving performance and data consistency. There are three main data warehouse architecture types.
The Three Tiers of Data Warehouse Architecture
- Single-tiered architecture: This warehouse architecture has a single layer – the source layer – and aims to reduce the volume of data. This data warehouse architecture has no staging area or data marts and is not implemented in real-time systems. This architecture type works best for processing organization operational data.
- Two-tiered architecture: A two-tiered architecture format separates the business layer from the analytical area, thereby giving the warehouse more control and efficiency over its processes. The two-tiered architecture contains a source layer and data warehouse layer and follows a 4-step data flow process:
-
- Metadata layer: The metadata schema/layer is where you can store the data on your data. This can be part of a successful data mesh strategy.
- Data staging: Transformations and data cleansing of the data from the source layer occur here. The data staging area acts as a short-term data storage location where ELT processes are performed on the data to clean, transform, process and validate it into the desired format for loading into the data warehouse. However, every change to the ongoing pipeline should not result in repeated cleaning and transformation of the entire dataset, as this is resource-intensive and inefficient. A good practice is to employ change data capture (CDC) or slowly changing dimensions (SCD). With CDC, the staging layer keeps a record of all changed data. Only this changed data gets ingested and undergos transformation and processing, severely reducing compute load, reducing latency, and improving operations’ efficiency.
- Data warehouse layer: Data from the staging area enters the data warehouse layer, which can act as the final storage location for historical data or be used to create data marts. This data warehouse layer may also contain a data metadata layer that contains information and context about the data stored in the data warehouse for better consumption by analysts and end-users. This information may include data sources, access procedures, data staging, users, and data mart schema.
- Three-tiered architecture: This architecture has three layers: the source, reconciled, and data warehouse layer. The reconciled layer in this architecture sits between the source and data warehouse layer and acts as a standard reference for an enterprise data model. However, although this layer introduces better data quality for warehouses, the additional storage space incurs extra costs.

Best Practices for Data Warehouse Architecture
Data warehouses house massive volumes of data, leading to high latency and low performance if engineers fail to follow the best practices. Here are some best practices to maintain when designing data warehouses:
- Utilize materialized views to reduce latency and improve performance: Materialized views represent a stored pre-computed dataset obtained from a query. Materialized views reduce the compute costs as stored query results are returned instead of running queries against entire datasets. Thus, results are returned within a short period, thereby improving performance and reducing latency. However, knowing when and why to utilize materialized views is vital as costs can increase quickly. Materialized views are ideal for situations where query results contain a small set of rows/columns, require significant processing, and where the base table doesn’t change frequently.
- Separate compute and storage duties: This separation of responsibilities helps save costs from massive compute workloads usually performed on data warehouses. Snowflake utilizes this design pattern. Another option is to store your data in long-term storage options like google cloud storage, AWS S3, and Azure storage and perform data ingestion to your data warehouse from these storage locations.
- Know your data model: Before mapping out a data warehouse architecture for your organization, business stakeholders and engineers must meet and evaluate the organization’s data needs. This practice helps know what data is valuable and what is not.
- Determine your organization’s data flow: Seamless data flow to data warehouses is crucial to the overall success of the data warehouse and the pace of decision making. Understanding this flow and business end use case for the data stored in warehouses helps design a warehouse that facilitates easy data flow and exchange between departments in an organization. For example, end-use cases involving real-time applications may employ a lambda architecture for its design that combines streaming and batch processing for data transformation.
- Employ automation for faster and agile operations: Manual processes introduce errors and can be time-consuming for organizations dealing with huge volumes of data. Utilizing tools for specific procedures like ETL and monitoring helps increase the pace of operations and reduces the risk of errors.
- The integration layer should be source agnostic: Since data warehouses are a result of data integrated from multiple sources, the layer that connects to these resources must be able to connect to various data sources and simultaneously align with the business model.
Principles of Data Warehouse Architecture
Data warehouses should fulfill the following properties in their architecture design:
- Separation of layers: Introducing layers into your data warehouse architecture helps ensure more effortless scalability and makes it easier for the warehouse to adapt to growing data needs. The layering of data warehouse architecture also forms a data mesh strategy for data-driven organizations.
- Scalable: Data sources tend to increase with time. The chosen data architecture should be able to scale independently to increase data volumes. Cloud data warehouses present easy scalability over traditional data warehouses.
- Resilient to change: Modern data warehouse environments must be resilliant to changes in the schema and structure to avoid pollution of data sets and downtime of ETL/ELT processes
- Extensive and support new integrations: Data warehouse architecture should be vast and support new integrations easily, without having to design the system from scratch.
- Secure: Data warehouses house critical and sensitive data, which may lead to strict compliance and safety issues if not well secured. The architecture should possess end-end security to ensure proper protection as the data flow between layers.
- Manageable: Easy management ensures easy monitoring and traceability in case of errors. Choosing a complex data warehouse architecture means more time spent monitoring and ensuring traceability of the warehouse pipeline.
Data Marts: Customized Mini Data Warehouses
Most layered data warehouse architecture contains a specialized, virtualized view of data that caters to a particular group of users within an organization.. This more focused, data subset refers to data marts.
For instance, the finance department may decide to want to perform predictive analysis for some of its customers. In this case, engineers may use a specific subset of consumer data from the data warehouse to create a data mart that best serves this model purpose. In this case, it eliminates unnecessary data, which hastens business intelligence and analysis.
Data marts are essential due to the following reasons:
- Faster data access: Imagine a scenario whereby a marketing analyst is looking to obtain insights from a specific email marketing campaign; thumbing through an entire complex dataset containing all organization data becomes time-consuming and resource-intensive. With datamarts, teams can quickly access subsets of the data from the enterprise data warehouses, integrate with other sources, and get started analyzing or drawing insights.
- Faster decision making: Data marts translate to faster data insights at a departmental level. Instead of taking more extended periods drawing insights from massive organizational data, data marts store data that focus on a specific department’s needs, like finance, and draw insights concerning it.
- Agility in operations: Data marts create a single source of truth whereby team members can access past and present data for use in mapping out strategies for business operations.
- Short-term analysis: Data marts are excellent for performing short-term analysis that doesn’t require access to the whole organization’s data. Teams can quickly set up data marts to get started on such projects.
Architecture differences between cloud and on-premise data warehouses
Today, the cloud is often part of modern data warehouse architecture. Let’s look at some of the differences between on-premises and cloud data warehouses.
Cost and Ease of Adoption
Traditional data warehouses can be capital and time intensive due to the costs of acquiring, setting up hardware components, and human resources to operate these hardware components. For cloud data warehouses, companies can easily set up their data warehouses by leveraging data warehouse solutions provided by cloud providers like AWS and Google Cloud at a non trivial fraction of the cost.
Maintenance Costs
With complete control comes total responsibility. For on-premises/traditional data warehouses, the perks of maintaining full control mean that the burden of ensuring high performance, efficient operations, and reducing downtime rests solely on their shoulders. Hence, this control creates additional work for engineers. For cloud-hosted data warehouse solutions, cloud service providers have a set Service Level Objective (SLO) for uptime, and ensuring availability and maintenance is a shared responsibility.
Speed and Performance
Traditional data warehouses are said to possess faster performance as the presence of dedicated hardware eliminates the restrictions on throughput and I/O on the disk side. However, because most disk capacity grows faster than the I/O throughput rates provided by these disks, more disks are needed to serve an acceptable performance for an increased number of users. Also, because it’s challenging to estimate the I/O bandwidth for a DW before building, a sudden increase in users requiring more I/O bandwidth for fast performance becomes an issue for on-premises DW, as acquiring more storage capacity is expensive and time-consuming. On the other hand, for cloud data warehouses, scaling up storage to improve performance takes minutes. Also, most cloud providers offer multi-location redundancy that helps speed up network access in multiple locations to serve a broad audience.
Scalability and flexibility
Cloud data warehouses can scale up and down in minutes according to fluctuations in volumes according to the demand of their applications. However, this fast scaling isn’t the case for traditional data warehouses, as users are forced to manage to a series of limitations imposed by the hardware.
Ease of Integrations
Cloud data warehouse design easily supports the automatic integration of new data sources like databases, social media, and other cloud applications. On the other hand, combining various data sources in your traditional data warehouse can be tedious and requires massive setup and hardware, which is a time-intensive venture. For cloud data warehouses, data integration becomes seamless by using the over 100 StreamSets connections. Additionally, most modern data warehouse cloud solutions come with in-built monitoring and optimization tools to help monitor the performance and health of your data warehouses. However, engineers face the burden of performing integrations and monitoring for traditional data warehouse solutions.
Disaster Recovery
On-premises data centers require backup centers to house duplicate data in case of disasters. These backup centers introduce additional hardware acquisition, setup, and maintenance costs. In most cases, backup centers may never be used and have no protection against the occurrence of natural phenomena like natural disasters. Most cloud data warehouses are inherently redundant in design and support duplication of data, snapshots, and backups in disaster cases.
Data Warehouses vs. Data Lakes vs. Data Lakehouses.
Other solutions for storing massive amounts of data include data lakes and lakehouses.
Unlike data warehouses with the primary purpose of storing large amounts of processed data for performing business analytics and business intelligence, the end use cases for storing in data lakes is flexible access to RAW data. Instead, data lakes help keep massive volumes of data without a predefined structure.
Data lakes store massive amounts of data (structured, unstructured, and semi-structured). At the same time, data warehouses store vast amounts of processed and filtered data for use in analytics.
A data lakehouse combines the best features of data warehouses and data lakes to provide a more robust and scalable storage solution. Data lakehouses combine the massive scale and cost-efficiency of data lakes with the ACID transactions of data warehouses to perform business intelligence and analytics on data. An example of a data lakehouse is the Databricks Lakehouse.
Conclusion
StreamSets helps drive quick and tangible value to your data warehouse by providing 100s of pre-built source connections and an easy to operate GUI-based design interface. This opens up the value to large groups of stakeholders with varying skillsets.
With automated jobs, you can automate StreamSets pipelines to deliver data to your data warehouse and sources that support change data capture. Multi-tale updates mean you don’t have to wrestle with your schema design when updating or migrating a data warehouse. You simply press play on your smart data pipeline and your schema will populate correctly. Last, whether you standardize on a data warehouse, a data cloud, or a data lakehouse, StreamSets supports these platforms with the same features and a unified developer experience.
