As John Zada puts it, “There can seldom be just one explanation to things. As a result our paradigms can be over-simplistic, incomplete or inaccurate – removing the complexity from the world which is actually one of its defining qualities.” So can we really evaluate such impactful tools in such simplistic terms?
Database to Data Warehouse: How It All Began
Companies have long posited the merits of building large scale data infrastructure to support their analytics teams and goals. Operational databases are perfect for collecting data from applications and storing it for reference, but poor for running analytical queries on the same data. That is why many companies invest in separate data platforms for running analytics. In 1993 the practice was forever changed when Ralph Kimball released the first version of The Data Warehouse Toolkit. The previous modeling practice was adequate for accounting for the linear placement and changing of data but lacked the ability to represent complex relationships between data. This was the area where dimensional modeling really excelled and for that became the fundamental principle for building a data platform for analytics.
A data warehouse, also known as an enterprise data warehouse or EDW, is a central repository of information that can be analyzed to make better informed decisions. Data flows into a data warehouse from transactional systems, relational databases, and other sources, typically on a regular cadence. Business analysts, data scientists, and decision makers access the data through business intelligence (BI) tools, SQL clients, and other analytics applications. It is a key canonical architecture if you aspire to be a data driven company. Software giants like IBM and Oracle devised large, expensive offerings for data warehouse infrastructure that provided both the servers, software, and services needed for descriptive analytics. At the same time, companies rushed to hire EDW administrators who were in charge of building the schema and strategizing how all data should flow into the data warehouse. However, the data warehouse quickly became associated with its limitations, as companies became hungrier to leverage more and more data. The data warehouse became crowded and bogged down with requests which killed its performance and tested its ability to deliver on service level agreements. Thus enterprise data warehouse became a four letter word. This largely fueled the invention of the data lake, which aimed to solve the problem of scale. But was the data lake the real replacement of the data warehouse?
The Rise of the Data Lake
A data lake is a data platform for semi-structured, structured, unstructured, and binary data, at any scale, with the specific purpose of supporting the execution of analytics workloads. A data lake often refers to a data storage system built utilizing the HDFS file system and commonly referred to as Hadoop. The founders of Hadoop were all practitioners of the enterprise data warehouse ecosystem at tech companies (Google and Yahoo). They wanted analytics at a larger scale and implemented in a more cost effective way than traditional data warehouse solutions. Companies with a data lake could now collect all the data they wanted without worries of capacity or schema uniformity and the rush to transition to a data lake architecture was on. Take for instance this graphic below which shows the Google search trends for the two topics between the years of 2005 and 2014.
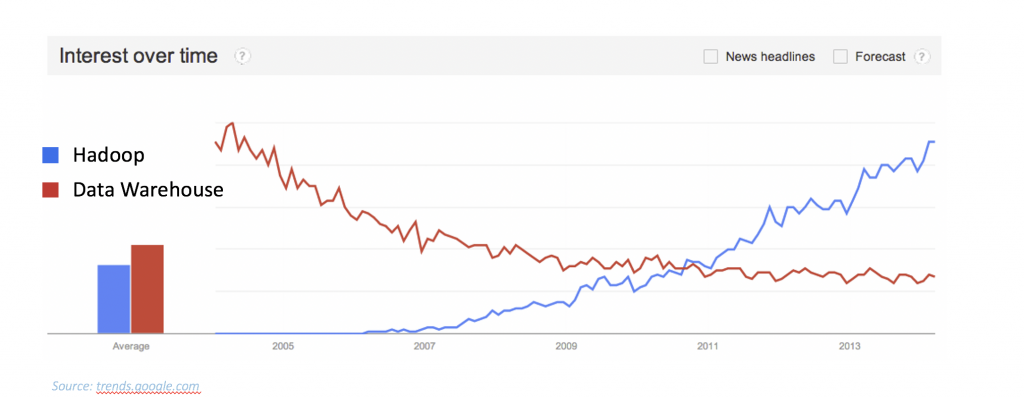 At first blush it would look like Hadoop overtook the data warehouse market, but in practice, that never happened. Ralph Kimball in 2013 amended The Data Warehouse Toolkit to include the concept of a Data Lake, a key point of validation. However, most companies chose to keep their data warehouse and build a data lake for largely unstructured and streaming data. This was actually a smart decision because in reality a data warehouse and data lake are good for slightly different things, both of which are relevant to a modern data architecture. In addition, Hadoop came with its own set of challenges. It was often hard to operate, requiring very specialized and high demand skills. Many companies struggled to get quick value and retain data lake professionals which made the cost of owning a data lake heavy on other dimensions. So did these companies make a mistake? Or was it rather something that may have not yet been clear at the time.
At first blush it would look like Hadoop overtook the data warehouse market, but in practice, that never happened. Ralph Kimball in 2013 amended The Data Warehouse Toolkit to include the concept of a Data Lake, a key point of validation. However, most companies chose to keep their data warehouse and build a data lake for largely unstructured and streaming data. This was actually a smart decision because in reality a data warehouse and data lake are good for slightly different things, both of which are relevant to a modern data architecture. In addition, Hadoop came with its own set of challenges. It was often hard to operate, requiring very specialized and high demand skills. Many companies struggled to get quick value and retain data lake professionals which made the cost of owning a data lake heavy on other dimensions. So did these companies make a mistake? Or was it rather something that may have not yet been clear at the time.
The Problem with Data Warehouse vs Data Lake
The problem with this paradigm is that it considers one approach wrong while the other is right when in practice companies may choose to leverage a data lake or data warehouse both for foundationally sound reasons. Here are some thoughts…
When to Use a Data Warehouse
- Query performance
- Transactional reporting
- Dashboards
- Structured data
- Data integrity
When to Use a Data Lake
- Large data volumes
- Unstructured and semi-structured data
- Streaming and time relevant data
- Data archive
Using a Data Lake and Data Warehouse for Analytics
Another way to think about it is from the analytics view point. Let’s take an example of a retail store that wants to know more about their customers so they can provide personalized offers. In order to put together a customer profile, the company may use data like transaction history, purchase history, address, name, etc. These are all structured data sources that often live in the enterprise data warehouse (System of Record) and might feed things like company dashboards. Other data like website traffic, social media data, geolocation data, and mobile app clickstream data are all unstructured sources and would likely live in the data lake (Systems of Engagement). Each set of data in a silo only reveals part of the story. For instance, it’s great to know if people are talking favorably about you on social media, but knowing if John Smith is talking about you favorably allows you to act on it. In order to know this, you need to marry together the siloed data.
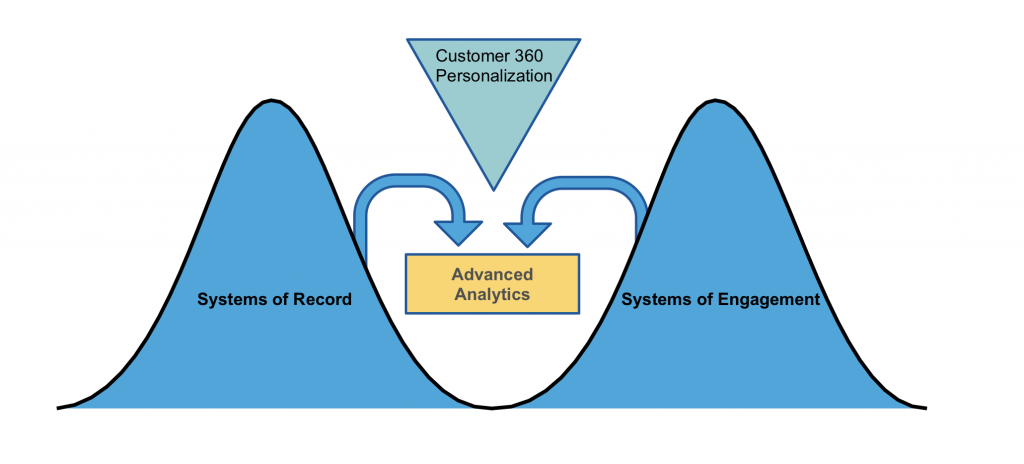 By merging these data sources the company can identify the user, their behavior, and design automated actions to deliver personalized responses. By leveraging the strengths of both platforms, companies can better utilize their people skills, their platform budgets, and their data governance.
By merging these data sources the company can identify the user, their behavior, and design automated actions to deliver personalized responses. By leveraging the strengths of both platforms, companies can better utilize their people skills, their platform budgets, and their data governance.
From Enterprise Data Platform to Cloud Data Platform
The public cloud came, and it changed everything about data and analytics with cloud data warehouse integration. Many of the constraints of the enterprise data warehouse were associated with hardware server limitations. When services like Snowflake and Amazon Redshift were launched they provided a level of scale and performance that were uncharacteristic of traditional data warehouse solutions. Cloud data lake services also removed many of common obstacles for users, including managing the complex noded architecture, and supplying services that removed much of the complexity of operating a data lake. This gave way to the concept documented by EMA research called The Unified Analytics Warehouse which states:
“Within a few years, nearly every organization that ran a data warehouse also stood up a data lake. The two existed side by side. Initially, there was some data sharing between the two platforms, but not much more. Pressured by customer demands to run analytics across both the data lake and the data warehouse, vendors on both sides began working toward a more complete integration of a warehouse and lake.”
Two common approaches by modern vendors took form to address this: the data platform approach (e.g. Snowflake, Amazon, Microsoft, Google, and Databricks) and the query approach (e.g. Dremio, Kylogence, and Asima). Depending on the competency centers of the organization they may choose a platform approach or a query approach depending on what will best facilitate the skills on their teams. These approaches provide a unified approach to data analytics where the style, structure, and source of data is less of a concern. Given this new found uniformity it might be difficult for you to identify which solution is best for your organization, but to that challenge I have promising news.
StreamSets Lets You Choose
StreamSets provides a modern data integration platform for data pipeline automations. Smart data pipelines are designed to connect to any database, data warehouse, or data lake service and provide quick value by making sure these platforms are full of useful, reliable, and current data. Smart data pipelines facilitate intent-driven design, which means that you build the pipelines with a focus on the needed flow and transformations for the data and worry about the platform destinations later. You can design for any paradigm and reverse your course when the strategy changes. An important feature for data engineers who may have to spend a majority of their time changing pipeline dynamics when destinations change. Not only does StreamSets support all major data warehouse and data lake platforms including cloud services, but users can actually build pipelines to multiple destinations.
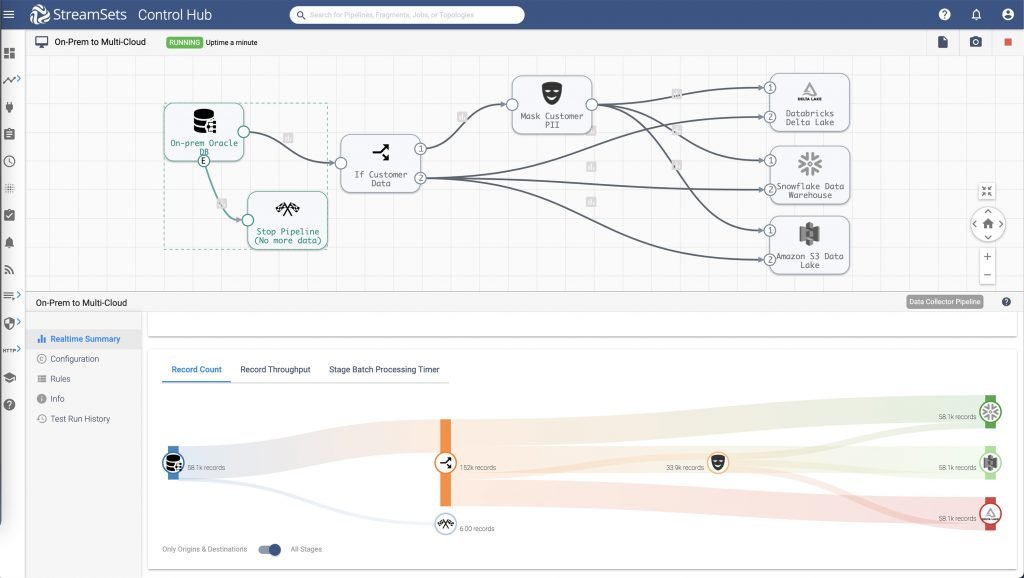 So if you are still unclear about the best solution for your data and analytics needs then mitigate your risk with smart data pipelines. They put you in control and remove the risk of being locked into a trend that no longer serves you. Because with smart data pipelines the only attachment may be personal and as John Zada writes “humans are not particularly flexible when it comes to using their paradigms. Deep down we are creatures of habit and sometimes obsession.”
So if you are still unclear about the best solution for your data and analytics needs then mitigate your risk with smart data pipelines. They put you in control and remove the risk of being locked into a trend that no longer serves you. Because with smart data pipelines the only attachment may be personal and as John Zada writes “humans are not particularly flexible when it comes to using their paradigms. Deep down we are creatures of habit and sometimes obsession.”