The modern data stack is less like a stack and more like an ecosystem with many participants. This constellation of technologies coalesces around a few guiding principles.
Three Guiding Principles
The first principle of the modern data stack is complete customizability. Eschewing a one size fits all solution, the modern data stack allows for data teams to pick and choose services across each layer. This means that the modern data stack can be as simple or complicated as an organization’s requirements.

The second principle is that to be part of the modern data stack your solution must be cloud-native to be part of the modern data stack. The reasoning is obvious: both cost and time efficiency. On-prem systems need teams to implement, update and manage them. Scaling with on-prem systems can be very difficult due to even minor changes potentially causing outages. On the other hand, cloud tools allow for out-of-the-box functionality that quickly gets users up and running. Scaling both up and down can often happen with the push of a button. Gone is the need to hire whole teams to perform maintenance. Instead, resources and focus can be redirected towards what really matters to a business.
The third principle holds that domain experts should be the ones acting on data, i.e., the people closest to the data should transform, store, define, and bring it to the surface for analysis. This is opposed to the past models where data engineers or IT organizations would supervise and control these processes on behalf of domain experts. Known throughout the stack as the democratization of data, this principle weaves through each layer of the modern data stack.
In summary, the principles of the modern data stack are:
- Customizable
- Cloud-native
- Democratized
The Layers of a Modern Data Stack
Data Mesh
The concept of data mesh is the result of two competing ideologies: a centralized or decentralized approach to data warehousing.
- Centralized: Send all your data to a centralized data warehouse and apportion access to grateful departments like the benevolent data steward that you are.
- Decentralized: Spread your data into many separate warehouses owned and operated by the subject matter experts.
The mesh in data mesh describes how these decentralized, separate warehouses operate together to form the data strategy of an organization.
There are several vendors that have claimed to be purveyors of data mesh, but it’s more like a data strategy than it is a product.
Cloud Data Warehouses and Data Lakes
Cloud data warehouses represent the heart of the modern data stack. Depending on the philosophy that your organization embraces, cloud data warehouses can either represent the primary place your organization consumes its data or one of many decentralized locations your data is stored. The cloud data warehouses that everybody uses today include Snowflake, Google BigQuery, Redshift, Databricks, and Azure Synapse.
Honorable mentions in the data stack include data lakes like S3 and HDFS. These alternative places to park your data do have their downsides, because of the difficulty in wrangling data into actionable insights. What do I mean by this? A data warehouse is like folding your clothes neatly and putting them into a dresser, where a data lake is like tossing them all into a pile in your closet and shutting the door. You save some time on the front end when it comes to putting your data (or your clothes) away, but it is a lot easier to get ready for work when everything is orderly. Data Lakehouses can provide this layer for the best of both worlds.
Data Integration
In the modern data stack, data engineers are moving away from legacy data integration methods like scripting. No code or little to no code data integration tools lower the technical barrier for entry and allow non-technical domain experts to be in control of their own data.
There are a few tools in the data integration layer that make use of API’s to move data from one location to another. These include Fivetran, Stitch, and Airbyte. The limitation of these tools is often they only function in one direction; for example, you can move data with a connector from Salesforce to your data warehouse but not the other way around. (See the section on reverse ETL).
Furthermore, these tools often only support batch processing, meaning you can set your integration to run at a specific time, usually once a day, and you process your data as a batch. The alternative is streaming ETL, which is the process of doing ETL in real time. Amazon Kinesis and Apache Kafka are popular frameworks to stream data. In addition, there are some modern techniques that support real-time processing, including Change Data Capture (CDC) and Slowly Changing Dimensions, built into many cloud data warehouses. Only a few data integration companies can support all of these frameworks and techniques. SteamSets is one.
The final limitation of the tools mentioned above is that they only do the EL part of ELT. They can extract and load, but the transformation has to happen elsewhere with another tool. In this segment of the layer, dbt is a popular choice. Dbt allows users to transform complicated data with nothing but SQL. But, again, a single-use tool has its drawbacks.
Comprehensive and modern ETL no-code services are rare. In this space, Informatica, Mattilion, Talend, and StreamSets are the front runners.
Event Tracking
Event tracking describes the process of collecting data on users of websites and applications. Event tracking can be done as a part of an ETL system, or the two processes can be broken down into individual services depending on how distributed or centralized an organization’s data strategy is. Independent event tracking services are called Customer Data Platforms (CDP). Leaders in this field include Segment, Snowplow, and Rudderstack.
Business Intelligence (BI)
Dashboarding tools like Looker, Tableau, and PowerBI are the big players in the BI layer. These advertise self-serve insights and the idea that anybody in a company should be able to learn something from their data. There are some cool new entrants into this layer that capitalize on the democratization of data, including Metabase, which does not require any SQL knowledge whatsoever. On the other side of the coin, this layer also contains tools for deeper analytics like Hex that are aimed at creating data models for a smaller, more focused, and more technical audience.
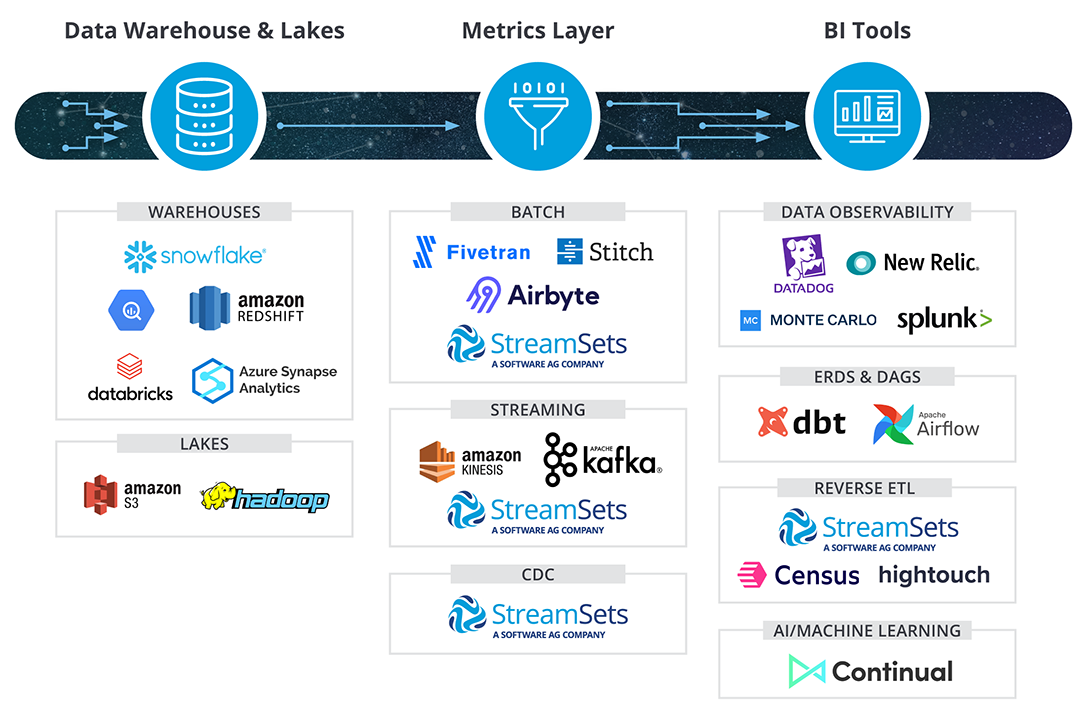 The metrics layer is intrinsically bonded to BI. Consensus has come to define it as a set of standard data definitions on top of BI tooling. A sort of company-wide data dictionary that helps users standardize terms across all their dashboards. It cannot exist on its own, which has inspired several opponents of this layer to wonder if it is even necessary. That being said, several tools have moved into this layer, including dbt.
The metrics layer is intrinsically bonded to BI. Consensus has come to define it as a set of standard data definitions on top of BI tooling. A sort of company-wide data dictionary that helps users standardize terms across all their dashboards. It cannot exist on its own, which has inspired several opponents of this layer to wonder if it is even necessary. That being said, several tools have moved into this layer, including dbt.
Data Observability
Data Observability is the pattern of activities using traces, logs, and other metrics to monitor the health of data. The players in this space are Datadog, NewRelic, Monte Carlo and Splunk. Successfully implemented, these tools allow data teams to troubleshoot issues with their data across each layer of their tech stack in real time. The goal is to automatically uncover data drift, schema changes, and other outliers before impacting users, which is why communication between the layers then is key. Some tools in the stack can identify these shifts in the data at the source, which can speed up remediation. StreamSets operates in this way, with data observability continuous and spread throughout the stack. Not just a data integration platform, StreamSets Control Hub, the control layer of StreamSets, operates as a monitoring, deployment and orchestration system.
The concept of data catalogs have largely been replaced in the modern data stack by data observability tools. That being said, there is still a place for programmatically-generated ERDS or data-heritage DAGS from tools like dbt and Airflow. Indeed, any tool in the modern data stack should be self-documenting by making metadata available for consumption. This new breed of automatically generated documentation ensures that your documentation will always match your code. A relief, I’m sure, to most.
Reverse ETL
Reverse ETL is the process of sending clean data from a data warehouse back into a third party application like Salesforce or Zendesk. There are startups in the modern data stack that specialize in reverse ETL, like Census and Hightouch. However, in my experience, a robust ETL tool should be able to handle stitching together data sources in any direction. StreamSets is one such tool.
AI/Machine Learning
Once you already have curated data governed by the people who know it best, the next logical step is to use that data to discover insights. In this layer, technologies like Continual democratize machine learning. Their position is that any data professional can become a machine learning engineer.
A Key Component of the Modern Data Stack
Principles of the modern data stack like observability, cloud-native, and data democratization guide a collection of technologies that create the stack needed for organizations to be truly data-driven. It’s unnecessary to choose a system from each layer all at once; instead organizations can pick and choose technologies as they grow. The simplest implementation could be a method of data integration and a cloud data warehouse; more complex integrations could involve technology from every layer of the stack.
StreamSets fits into this framework easily and can be part of a successful data strategy. We are cloud-based, and our low-code interface empowers data engineers across a broad range of skill levels. Best of all, we can scale with you as your data stack grows, because StreamSets can connect to almost any source or destination in the modern data stack.
