When we began investing in test automation several years ago, we were driven by a commitment to the quality of our products and by a need to enable our developers. Since then, our customers have let us know that they’re also interested in knowing about how we test our product suite and to see if they could leverage the ideas and tooling that we’ve developed for their own DataOps use cases. This blog is aimed at answering these questions.
Design Decisions
Within our engineering organization, we follow a process of test-driven development, which has given rise to the large collection of unit tests that live alongside our source code. These tests aid developers as they write new features and update existing ones, which often means using mocks to speed test execution time and simplify the development process. As our products and codebase grew, however, we recognized the need to test end-to-end scenarios that use real environments and execute actions from a user-facing perspective. This need has evolved into what we’re releasing to StreamSets customers today, a project that we call the StreamSets Test Framework (STF).
While StreamSets’ products are predominantly written in Java with corresponding Java-based unit tests, tests written for the StreamSets Test Framework use Python. This decision was made early on as a way to aid in test code readability, as well as to take advantage of the faster development time enabled by interpreted languages. This choice also meant that we could use the StreamSets SDK for Python within our tests, freeing us from our earlier process of committing pipeline JSON files into our test repositories in place of the more readable Python syntax described in a previous blog post. This intentional coupling also demonstrates our commitment to expanding the SDK to enable more customer use cases: if we left functionality out of the SDK, we wouldn’t be able to use it for our own internal automated testing, which would reduce our confidence in the quality of our products.
Framework Components
The StreamSets Test Framework is comprised of three separate but closely interconnected components:
pytest abstractions
The StreamSets Test Framework takes advantage of the powerful test idioms and execution environment provided by the popular pytest framework. By using powerful features like fixtures, test discovery, and assert introspection, pytest enables engineers at StreamSets to spend less time thinking about test execution and more time thinking about the tests themselves.
Libraries
Along with the aforementioned StreamSets SDK for Python, which provides a large collection of abstractions with which to interact with our products, STF incorporates a significant number of third-party Python client libraries. Users who want to verify that the data coming out of or going into their StreamSets pipelines is actually written into their JDBC database or Hadoop cluster, for example, can use the environment models we maintain to do so.
Docker integration
The StreamSets Test Framework takes advantage of Docker in two distinct ways.
First, as we’ve previously discussed, our team has long enjoyed the convenience of starting instances of StreamSets Data Collector containers. Beyond the existing Data Collector Docker images we’ve published to Docker Hub since SDC 2.3.0.1, we’ve opened a Docker Hub repository housing stage libraries for releases and nightly builds of Data Collector. Together, these allow STF tests to start Data Collector instances and make immediately available any stage libraries we need.
Second, STF itself runs out of a Docker image. This allows for easier deployment to our internal continuous integration system (the subject of a future post) by minimizing the number of dependencies required on our build machines. It also allows for more complete connectivity to other Docker-based environments against which we run our tests (again, the subject of a future post).
Test Walkthrough
Perhaps the easiest way to understand the StreamSets Test Framework is to look at tests that use it, so let’s do that now. Along with STF itself, we’ve made public our StreamSets Data Collector test repository on GitHub. For this example, we’ll dig into a simple one that exercises the JDBC Multitable Consumer origin and break it down piece by piece.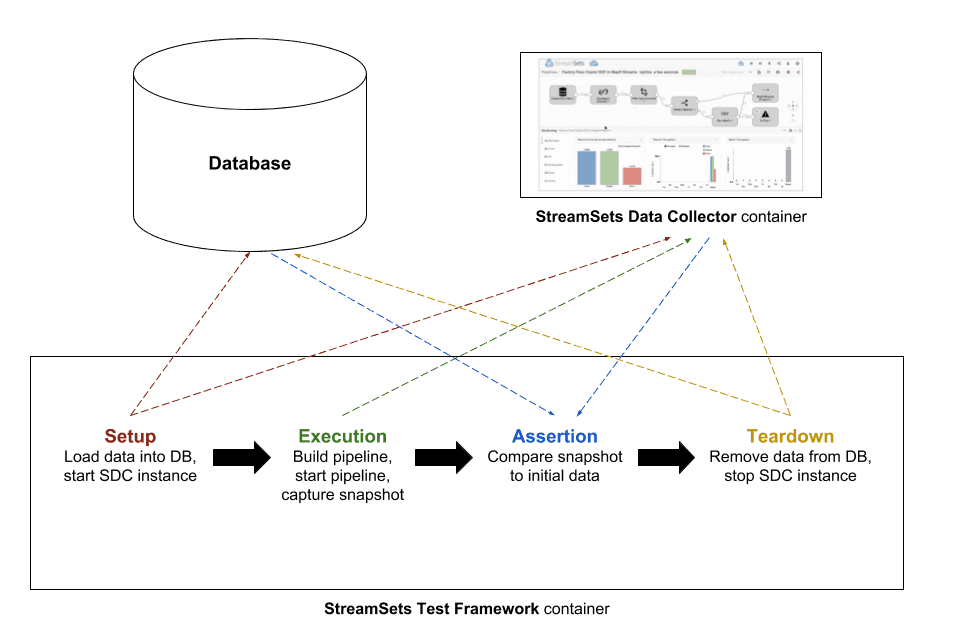
@database def test_jdbc_multitable_consumer_origin_simple(sdc_builder, sdc_executor, database):
The first line of this snippet shows how we use pytest’s marker functionality to annotate tests with external dependencies. These markers ensure that tests run without the required command line argument (in this case, a database URL) will simply be skipped.
The second line shows the test function declaration. The argument list demonstrates how we use pytest’s powerful fixture paradigm to handle resources (the STF documentation contains a list of all the fixtures that are available). sdc_builder refers to the instance of StreamSets Data Collector that creates any pipelines within the test and sdc_executor refers to the one that actually runs pipelines; by separating them in this way, nearly any of our functional tests can also be executed to test upgrade compatibility. The last argument, database , points to instances of classes we use to represent various databases (e.g. instances of MySQL or PostgreSQL, among others); we’ll show how this is used within the test a bit later.
src_table_prefix = get_random_string(string.ascii_lowercase, 6)
table_name = '{}_{}'.format(src_table_prefix, get_random_string(string.ascii_lowercase, 20))
pipeline_builder = sdc_builder.get_pipeline_builder()
jdbc_multitable_consumer = pipeline_builder.add_stage('JDBC Multitable Consumer')
jdbc_multitable_consumer.set_attributes(table_configs=[{"tablePattern": f'%{src_table_prefix}%'}])
trash = pipeline_builder.add_stage('Trash')
jdbc_multitable_consumer >> trash
pipeline = pipeline_builder.build().configure_for_environment(database)
This code should look familiar to existing users of the StreamSets SDK for Python; this is where the pipeline and its stages’ configurations are defined. What should look new is in the last line, where the Pipeline instance that we build now includes a configure_for_environment method. This method is how the Test Framework allows tests written agnostic to particular environments to successfully run against many of them. Most environment classes that we’ve created for STF include an attribute called sdc_stage_configurations , which lets us define which stage configurations may need to be altered to work against a given environment. This pattern provides a flexible way for us to pass things like command line options (e.g. credentials or connection strings) to tests on the command line.
metadata = sqlalchemy.MetaData()
table = sqlalchemy.Table(
table_name,
metadata,
sqlalchemy.Column('id', sqlalchemy.Integer, primary_key=True),
sqlalchemy.Column('name', sqlalchemy.String(32))
)
try:
logger.info('Creating table %s in %s database ...', table_name, database.type)
table.create(database.engine)
logger.info('Adding three rows into %s database ...', database.type)
connection = database.engine.connect()
connection.execute(table.insert(), ROWS_IN_DATABASE)
This block of code sees us creating a database table and inserting rows. For databases, we lean on the SQLAlchemy project, which provides a common API for interacting with numerous database types. By using this, a given STF test of one of our JDBC stages can run against any JDBC-compliant database. Also notice that we take advantage of Python’s try clause. We pair this with a finally at the end of the test so that if anything goes wrong, we make sure to clean up any environments we’ve modified in the course of the test.
sdc_executor.add_pipeline(pipeline)
snapshot = sdc_executor.capture_snapshot(pipeline=pipeline, start_pipeline=True).snapshot
sdc_executor.stop_pipeline(pipeline)
# Column names are converted to lowercase since Oracle database column names are in upper case.
rows_from_snapshot = [{record.value['value'][1]['sqpath'].lstrip('/').lower():
record.value['value'][1]['value']}
for record in snapshot[pipeline[0].instance_name].output]
assert rows_from_snapshot == [{'name': row['name']} for row in ROWS_IN_DATABASE]
finally:
logger.info('Dropping table %s in %s database...', table_name, database.type)
table.drop(database.engine)
This final snippet demonstrates the design pattern we use in most of our tests of origin stages. Having loaded data into an environment earlier in the test, we create a pipeline, run it, and then capture a snapshot of the data read by Data Collector. With this snapshot in hand, we can assert that the data seen by Data Collector is what we expect, completing the end-to-end test of the stage.
Installing the Framework
Before the test can actually be executed, we need to install the StreamSets Test Framework to enable the stf command for users. Ensure that you have Docker installed, a StreamSets SDK for Python license key in your home folder (available to customers as part of our Premium and Enterprise subscriptions), and Python 3.4+ available on your system and then run
$ pip3 install streamsets-testframework
Running the Test
To actually see the test in action, we use the stf build command to create a Docker image containing the libraries needed to communicate with our database before checking out the test source code repository from GitHub, setting it as our working directory, and invoking stf test. We also pass in details about the database we’d like to run against, specify the StreamSets Data Collector version to start up in the course of the test, add a flag to show output on the console, and narrow the scope to the test we care about:
$ stf build extras --extra-library jdbc $ git clone https://github.com/streamsets/datacollector-tests.git $ cd datacollector-tests $ stf test -vs --database mysql://mysql.cluster:3306/default --database-username mysql --database-password mysql --sdc-version 3.4.0 stage/test_jdbc_stages.py::test_jdbc_multitable_consumer_origin_simple 2018-09-08 03:40:09 PM streamsets.testframework.cli INFO Pulling Docker image streamsets/testframework:master ... 2018-09-08 03:40:11 PM streamsets.testframework.cli WARNING Network (cluster) already exists. Continuing without creating ... 2018-09-08 03:40:11 PM streamsets.testframework.cli INFO Running STF tests ... ============================= test session starts ============================== platform linux -- Python 3.6.6, pytest-3.0.4, py-1.6.0, pluggy-0.4.0 benchmark: 3.1.1 (defaults: timer=time.perf_counter disable_gc=False min_rounds=5 min_time=0.000005 max_time=1.0 calibration_precision=10 warmup=False warmup_iterations=100000) rootdir: /root/tests, inifile: plugins: benchmark-3.1.1 collected 10 items stage/test_jdbc_stages.py .
This walkthrough of a simple stage test demonstrates just some of what the StreamSets Test Framework makes possible. For more complete details, please take a look at the project’s documentation.
Next Steps
Astute readers may notice that, while we described how STF can interact with external environments, we glossed over the process by which we actually spin up these environments. In our next post, we’ll provide details about how we do this and share some of the tooling we’ve developed to make the process more reliable and efficient.