
Transformer for Snowflake is the first enterprise data transformation engine built on Snowpark. Want to learn how the engine makes advanced, native data transformations for your Data Cloud possible? Join our technical experts on Office Hours.
![]() As a Snowpark Accelerated partner, we’re excited to announce the preview of a new way to work with Snowflake: Transformer for Snowflake. StreamSets customers that use Snowflake and want to harness the extra power and flexibility of Snowpark (with the ease of StreamSets), take note!
As a Snowpark Accelerated partner, we’re excited to announce the preview of a new way to work with Snowflake: Transformer for Snowflake. StreamSets customers that use Snowflake and want to harness the extra power and flexibility of Snowpark (with the ease of StreamSets), take note!
What Is Snowpark?
Snowpark is the next big step in giving even more users the power to democratize data access with Snowflake’s Data Cloud. In preview now, Snowpark enables data engineers, data scientists, and developers who prefer languages like Scala and Java to take advantage of Snowflake’s powerful platform.
Now, instead of taking data out of Snowflake to run more sophisticated Spark-style code and transformations, data engineers and ETL developers can write code in languages more dynamic than SQL, that can then execute directly within Snowflake.
What Is the Transformer for Snowflake?
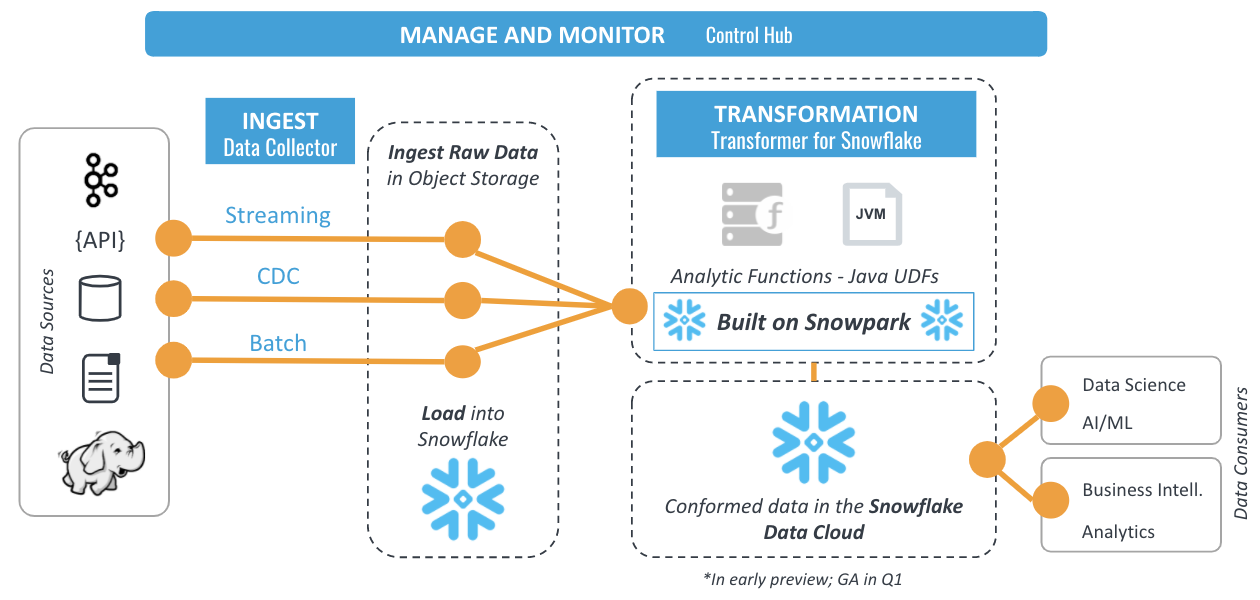
Transformer for Snowflake will build on top of Snowpark to enable both the expressiveness and flexibility of Snowpark’s multi-language support, as well as the simplicity of Data Cloud operations that were traditionally limited to SQL.
With this new tool, data engineers will be able to go beyond SQL to express powerful data pipeline logic with the StreamSets DataOps Platform. Utilizing Scala or Java through an intuitive graphical interface, they can choose no code, or drop-in code when they want.
Transformer for Snowflake will provide all the benefits of StreamSets DataOps Platform with built-in monitoring and orchestration of complex data pipelines at scale. And it will do so in the cloud, with no additional hardware required.
How to Increase the Value of Your Snowflake Data Cloud
Many Snowflake customers currently use the StreamSets DataOps Platform to build and operate smart data pipelines that ingest streaming, batch, or change data capture (CDC) data pipelines into the Snowflake Data Cloud. With the addition of Transformer for Snowflake, Snowflake customers will be able to get even more out of their Data Cloud investments by:
- Eliminating the need for additional Spark-based systems that add cost, complexity, and latency with a high-performance data engineering platform harnessing the power and flexibility of Scala while executing entirely in Snowflake’s Data Cloud
- Building and orchestrating enterprise-grade data pipelines, combining the ease of drag-and-drop design with the extensibility of custom code and a comprehensive SDK that provides 10x productivity to data engineers
- Building, operating, and monitoring all pipelines for Snowflake’s Data Cloud, including streaming, CDC, and batch data pipelines ingesting data to the Data Cloud, as well as ELT pipelines executing workloads directly in the Snowflake Data Cloud via Snowpark
- Using smart data pipelines designed to deliver data continuously to support a DataOps practice in Snowflake and elsewhere, with built-in resiliency to changes in data structures, schema, and semantics
- Data engineering delivered as a cloud service with no infrastructure to build or manage
Learn more about how StreamSets and Snowflake work together. Or, go ahead and try Transformer for Snowflake now.
