Apache Spark Transformer
Configure and manage your ETL pipelines on Spark without hand coding.
Modern ETL Pipelines without the Complexity
Turn unlimited data into insights in minutes with StreamSets Transformer for Spark. StreamSets Transformer runs on any Apache Spark environment (Databricks, AWS EMR, Google Cloud Dataproc, and Yarn) on premises and across clouds. StreamSets Transformer for Spark is a data pipeline engine designed for any developer or data engineer to build and manage ETL and ML pipelines that execute on Spark.
Runs On
Run Apache Spark anywhere now and in the future as your needs evolve.




Operationalize Your Data Transformations
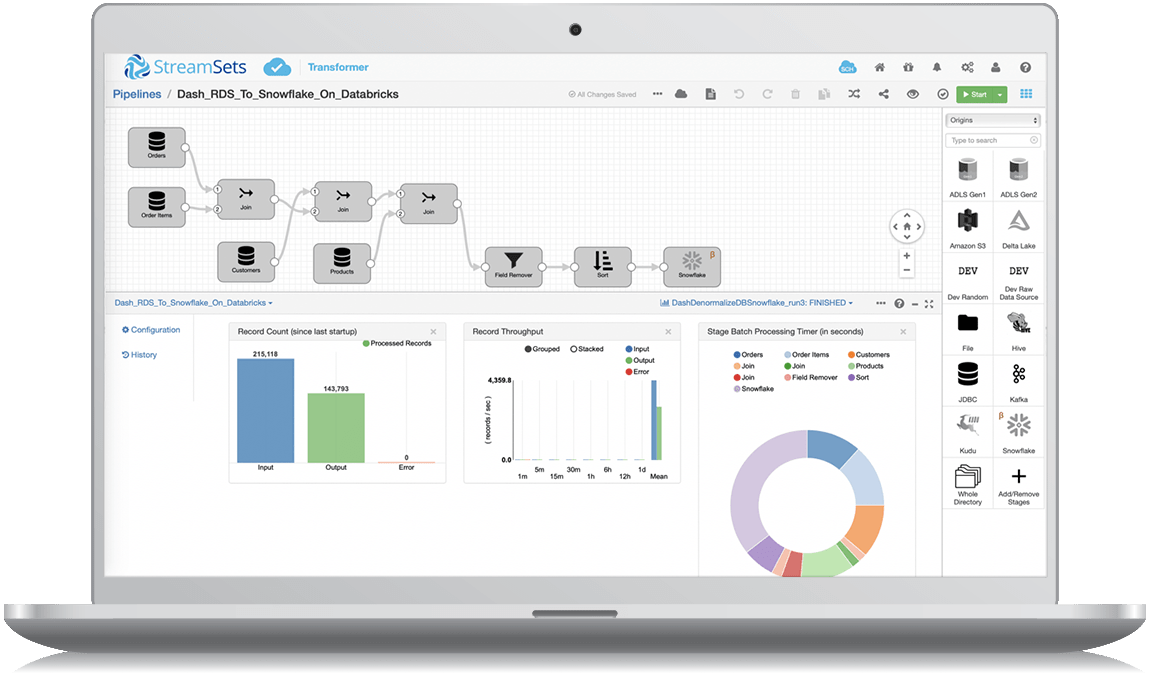
Build and Manage ETL and ML Pipelines That Execute on Spark
Put powerful and native ETL at the fingertips of any data engineer. Use a simple, drag-and-drop UI to create highly instrumented pipelines for performing ETL, stream processing, and machine learning operations. StreamSets Platform helps your team accelerate your data projects. Easily operationalize code and automate critical Spark operations through a central platform.
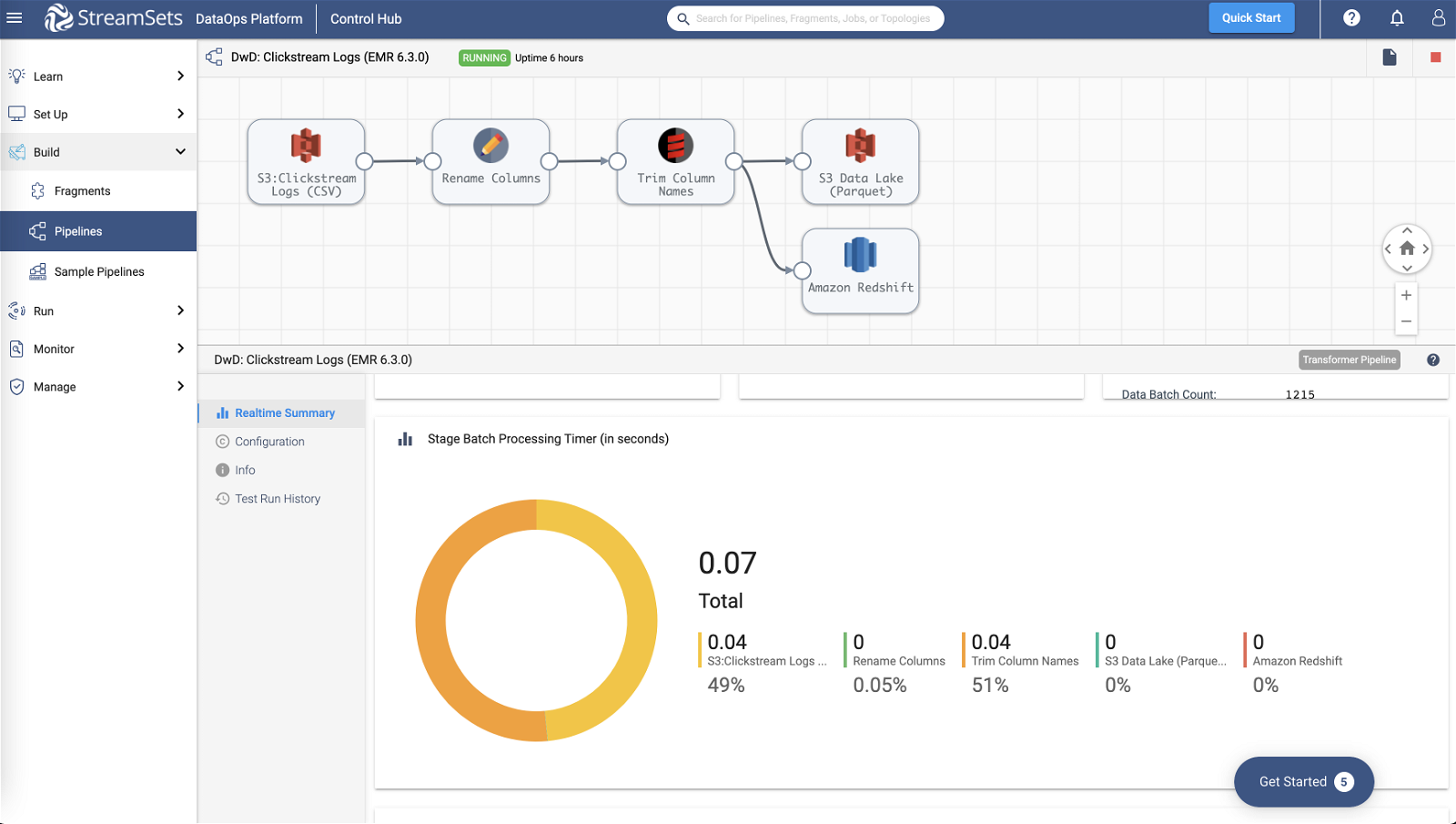
Run on Multiple Spark Platforms
Transformer Engines are designed to run on all major Spark distributions for maximum flexibility. You can natively execute on EMR, HDInsight, and Databricks platforms. Run your development and production projects on multiple Spark platforms or support different business unit needs from a single tool without rework.
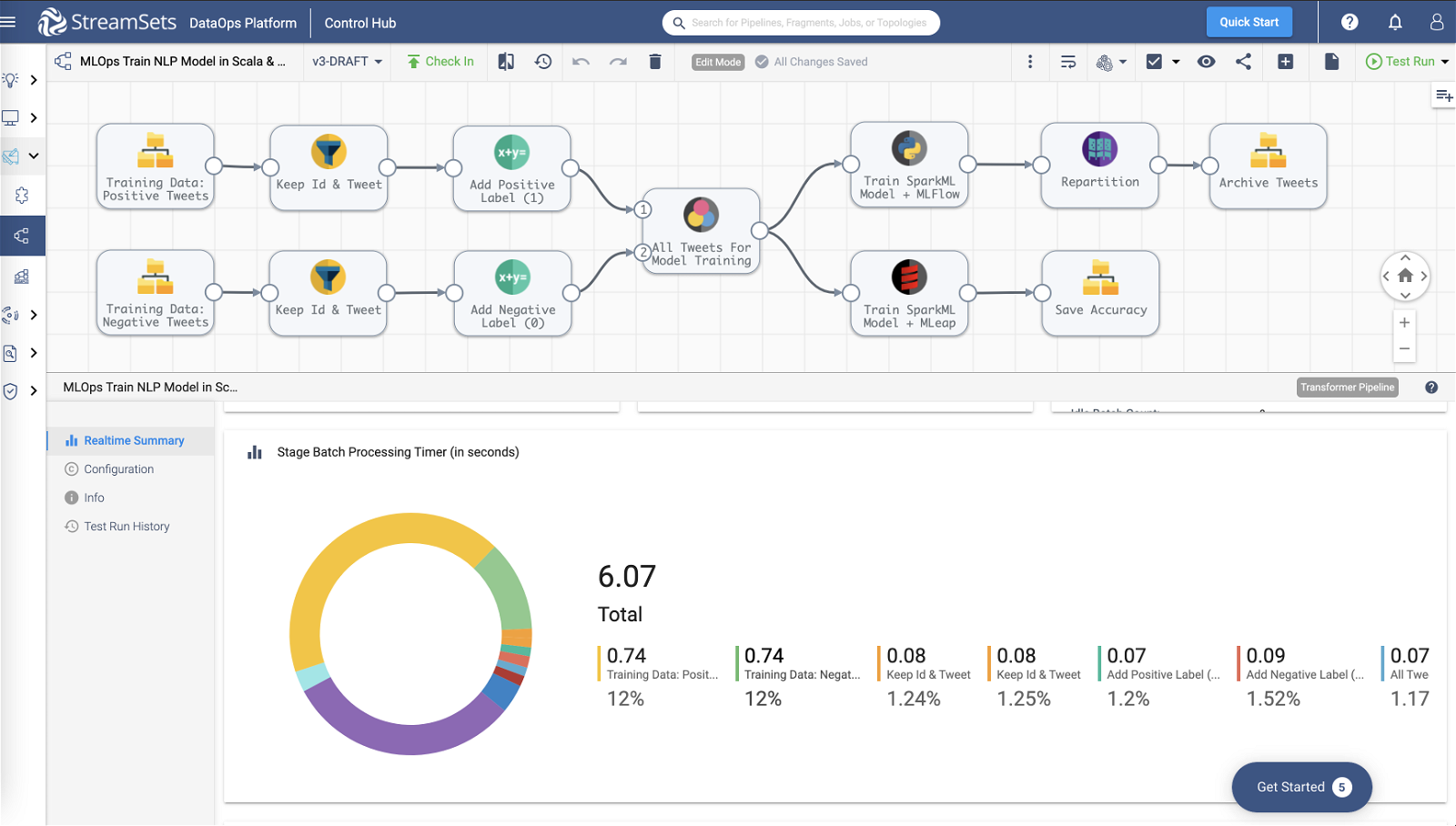
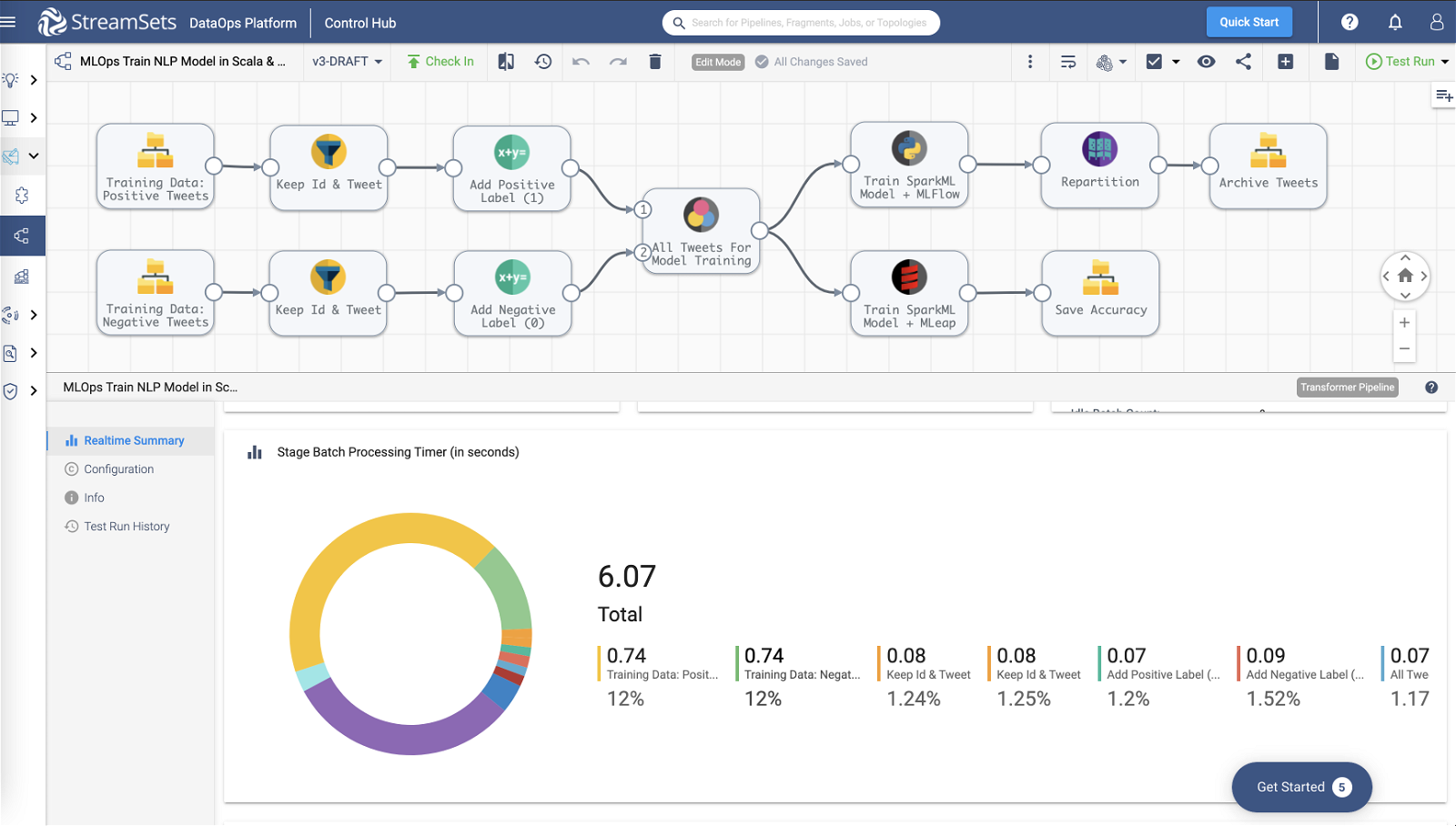
See What Changed and Respond Easily
Full visibility and unmatched resiliency in your pipelines means you can stop hunting through log files for errors when change happens. Transformer pipelines are instrumented to provide deep visibility into Spark execution so you can troubleshoot at the pipeline level and at each stage in the pipeline. Transformer offers the enterprise features and productivity of legacy ETL tools, while revealing the full power and flexibility of Apache Spark.

Awards and Recognition


Data Engineers Gain Efficiencies With StreamSets

![]() 8/1/23
8/1/23
"The best feature of StreamSets is its intuitive visual interface, allowing us to effortlessly design, monitor, and manage data pipelines without the need for complex coding. This has significantly reduced our development time and made the process highly accessible to both technical and non-technical team members."

![]() 8/3/23
8/3/23
"StreamSets has lot of out of box features to use for data pipelines and connect AWS Kinesis, DB or Kafka and send to HDFS & Hive."
Frequently Asked Questions
What is StreamSets Transformer for Spark?
What is a StreamSets Transformer for Spark pipeline?
All data pipelines for all of our engines, including Transformer for Spark, are essentially data flows. Taking data from one source to another and often including transformations along the way. Data pipelines can be leveraged to power machine learning, advanced analytics, business intelligence and other key insights.
Is StreamSets an ETL tool?
StreamSets acts as an ETL tool, though it is a complete end-to-end data integration platform. It performs ETL, ELT and data transformations such as joins, aggregates, and unions directly on Apache Spark and Snowflake platforms.
How do I create an ETL pipeline in Spark with StreamSets?
Transformer for Spark, StreamSets’ Spark Engine, acts as a Spark client that launches distributed Spark applications. Transformer passes the pipeline definitions and Spark runs it just as it would any other application, distributing the processing across nodes in the cluster. You can find more information on how to get started in the StreamSets documentation for Transformer.
Can I still run Python code on Spark with StreamSets?
Yes. StreamSets Transformer runs on any Apache Spark environment (Databricks, AWS EMR, Google Cloud Dataproc, and Yarn) on premises and across clouds. StreamSets Transformer for Spark is a data pipeline engine designed for any developer or data engineer to build and manage ETL and ML pipelines that execute on Spark.
How do I install StreamSets Transformer for Spark?
Installation information can be found in the Transformer Spark documentation..