Cloud Data Lake Integration
A data lake solution for any integration pattern.
You Need Data Now, Not Later
Modern analytics, data science, AI, machine learning…your analysts, data scientists and business innovators are ready to change the world. If you can’t deliver the data they need, faster and with confidence, they’ll find a way around you. (They probably already have.)
Data lakes hold vast amounts of a wide variety of data types and make processing big data before uploading to destinations like Snowflake and applying machine learning and AI possible. How can you ensure that your data lake integration delivers data continuously and reliably?

The StreamSets Smart Data Pipeline Advantage
Data integration for cloud data lakes requires more than an understanding of how to build what the business requests. The StreamSets data engineering platform supports your entire data team to quickly build smart data pipelines that are resilient to change for continuous data ingestion into your cloud data lake.
Flexible Hybrid and Multi-cloud Architecture
Easily migrate your work to the best data platform or cloud infrastructure for your needs.





What Is a Data Lake?
A data lake is a storage platform for semi-structured, structured, unstructured, and binary data, at any scale, with the specific purpose of supporting the execution of analytics workloads. Data is loaded and stored in “raw” format in a data lake, with no indexing or prepping required. This allows the flexibility to perform many types of analytics—exploratory data science, big data processing, machine learning, and real-time analytics—from the most comprehensive dataset, in one central repository.
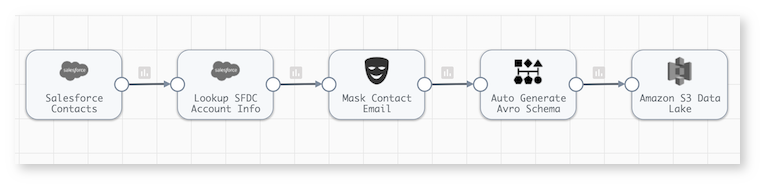
Basic Design Pattern for Cloud Data Lake Integration
Your cloud data lake is the gateway to advanced analytics. Once ingested, data can go in many different directions to support modern analytics, data science, AI, machine learning, and other use cases. A basic data ingestion design pattern starts by reading data from a data source, then routes the data with simple transformations such as masking to protect PII, and stores data in the data lake.
One of the challenges to implementing this basic design pattern is the unexpected, unannounced, and unending changes to data structures, semantics, and infrastructure that can disrupt dataflow or corrupt data. That’s data drift, and it’s the reason why the discipline of sourcing, ingesting and transforming data has begun to evolve into data engineering, a modern approach to data integration.

Smart Data Pipelines for Cloud Data Lake Integration
The Smart Data Pipeline Difference
The typical approach to building a data pipeline is to hand code or use tools that create significant dependencies on technical implementation details across the resulting data pipeline. Smart data pipelines are engineered to abstract away those details and decouple sources and destinations so you can focus on the “what” of the data and adapt easily to new requirements.

What Smart Data Pipelines Do
- Enable real-time transformation regardless of source, destination, data format or processing mode
- Multiplex and demultiplex to read tables with different schemas and write to partitions
- Enable stop and restart of the pipeline and failover at the execution engine
- Improve performance and simplify debugging with built-in preview and snapshots
- Gain real-time insight at the pipeline and stage level

Managing Infrastructure Change
The StreamSets approach to data integration and data engineering makes it possible to change infrastructure endpoints without starting over. For example, if the source of your data lake ingestion pipeline changes from an Oracle database to MySQL, you have 3 options:
- Duplicate the data pipeline and update the origin to keep both data pipelines active
- Create a new version of the pipeline, change the origin, to replace the existing pipeline with the option to revert
- Parameterize key attributes and run multiple instances of the same pipeline

Frequently Asked Questions
What is a data lake solution
A data lake is a storage platform for all kinds of data (semi-structured, structured, unstructured, and binary), at any scale, designed to support the execution of analytics workloads.
What’s the advantage of a cloud-based data lake?
There are several advantages of choosing a cloud-based data lake, including minimizing capital expenses for hardware and software, the ability to get new analytic solutions to market quickly, and the elimination of data silos by consolidating multiple data types into a single, unified, infinitely scalable platform.
Data Engineers Handbook for Snowflake
Design Considerations for Apache Spark Deployment
Ready to Get Started?
We’re here to help you start building pipelines or see the platform in action.