Drift Synchronization with StreamSets Data Collector and Azure Data Lake
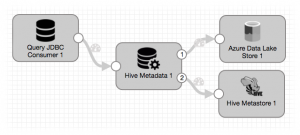 One of the great things about StreamSets Data Collector is that its record-oriented architecture allows great flexibility in creating data pipelines – you can plug together pretty much any combination of origins, processors and destinations to build a data flow. After I wrote the Ingesting Local Data into Azure Data Lake Store tutorial, it occurred to me that the Azure Data Lake Store destination should work with the Hive Metadata processor and Hive Metastore destination to allow me to replicate schema changes from a data source such as a relational database into Apache Hive running on HDInsight. Of course, there is a world of difference between should and does, so I was quite apprehensive as I duplicated the pipeline that I used for the Ingesting Drifting Data into Hive and Impala tutorial and replaced the Hadoop FS destination with the Azure Data Lake Store equivalent.
One of the great things about StreamSets Data Collector is that its record-oriented architecture allows great flexibility in creating data pipelines – you can plug together pretty much any combination of origins, processors and destinations to build a data flow. After I wrote the Ingesting Local Data into Azure Data Lake Store tutorial, it occurred to me that the Azure Data Lake Store destination should work with the Hive Metadata processor and Hive Metastore destination to allow me to replicate schema changes from a data source such as a relational database into Apache Hive running on HDInsight. Of course, there is a world of difference between should and does, so I was quite apprehensive as I duplicated the pipeline that I used for the Ingesting Drifting Data into Hive and Impala tutorial and replaced the Hadoop FS destination with the Azure Data Lake Store equivalent.