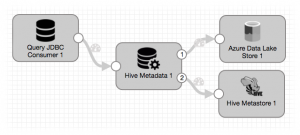
 One of the great things about StreamSets Data Collector is that its record-oriented architecture allows great flexibility in creating data pipelines – you can plug together pretty much any combination of origins, processors and destinations to build a data flow. After I wrote the Ingesting Local Data into Azure Data Lake Store tutorial, it occurred to me that the Azure Data Lake Store destination should work with the Hive Metadata processor and Hive Metastore destination to allow me to replicate schema changes from a data source such as a relational database into Apache Hive running on HDInsight. Of course, there is a world of difference between should and does, so I was quite apprehensive as I duplicated the pipeline that I used for the Ingesting Drifting Data into Hive and Impala tutorial and replaced the Hadoop FS destination with the Azure Data Lake Store equivalent.
One of the great things about StreamSets Data Collector is that its record-oriented architecture allows great flexibility in creating data pipelines – you can plug together pretty much any combination of origins, processors and destinations to build a data flow. After I wrote the Ingesting Local Data into Azure Data Lake Store tutorial, it occurred to me that the Azure Data Lake Store destination should work with the Hive Metadata processor and Hive Metastore destination to allow me to replicate schema changes from a data source such as a relational database into Apache Hive running on HDInsight. Of course, there is a world of difference between should and does, so I was quite apprehensive as I duplicated the pipeline that I used for the Ingesting Drifting Data into Hive and Impala tutorial and replaced the Hadoop FS destination with the Azure Data Lake Store equivalent.
It turned out, though, that my misgivings were unfounded and, with some careful configuration, my pipeline just worked! Here are the critical config properties for getting this working:
Hive Metadata Processor
Most of the configuration is as for the Hive/Impala tutorial, with the exception of:
Hive Tab
JDBC URL: jdbc:hive2://<your-hdinsight-cluster>.azurehdinsight.net:443/default;ssl=true;user=<username>;password=<password>?hive.server2.transport.mode=http;hive.server2.thrift.http.path=/hive2
Create a JDBC URL using your HDInsight cluster’s URL and the parameters shown above. You will need to use a suitable username and password for your HDInsight cluster.
Hadoop Configuration Directory: /path/to/local/copy/of/hadoop/config
SDC needs to access various Hadoop settings, so you’ll need to copy the Hadoop config files (including hive-site.xml) from an HDInsight head node to a local directory
Hive Metastore Destination
Again, set the destination up as for the Hive/Impala tutorial, except:
Hive Tab
JDBC URL: This should be the same as for the Hive Metadata Processor
Hadoop Configuration Directory: Again, copy this from the Hive Metadata Processor configuration
Azure Data Lake Store Destination
Configure the Data Lake tab exactly as in the Azure Data Lake Store tutorial.
Output Files Tab
Directory in Header: Unchecked
Directory Template: /clusters/<cluster-name>${record:attribute('targetDirectory')}
The Directory Template must start with the Root Path of the HDInsight cluster, followed by the targetDirectory record attribute. Be careful not to insert a slash between the two – at present this will trigger an error in the Azure Data Lake client library.
Use Roll Attribute: Checked
Roll Attribute Name: roll
The Roll Attribute tells the ADLS destination to ‘roll’ the output file – removing the _tmp_ prefix from the current output file and opening a new _tmp_ file for writing.
Data Format Tab
Data Format: Avro
Avro Schema Location: In Record Header
With this configuration, the Hive Metadata processor and Hive Metastore and Azure Data Lake Store destinations ‘just work’. Watch the pipeline in action in this short video:
Conclusion
StreamSets Data Collector‘s modular, record-based architecture provides great flexibility when creating data pipelines. Download SDC today, and get started building your own data pipelines with built-in data drift handling!