Create a Custom Expression Language Function for StreamSets Data Collector
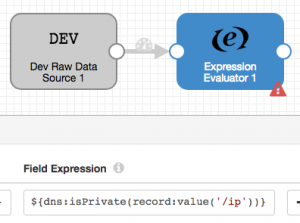 One of the most powerful features in StreamSets Data Collector Engine is support for Expression Language, or ‘EL’ for short. EL was introduced in JavaServer Pages (JSP) 2.0 as a mechanism for accessing Java code from JSP. The Expression Evaluator and Stream Selector stages rely heavily on EL, but you can use Expression Language in configuring almost every SDC stage. In this blog entry I’ll explain a little about EL and show you how to write your own EL functions.
One of the most powerful features in StreamSets Data Collector Engine is support for Expression Language, or ‘EL’ for short. EL was introduced in JavaServer Pages (JSP) 2.0 as a mechanism for accessing Java code from JSP. The Expression Evaluator and Stream Selector stages rely heavily on EL, but you can use Expression Language in configuring almost every SDC stage. In this blog entry I’ll explain a little about EL and show you how to write your own EL functions.
 There has been an explosion of innovation in open source stream processing over the past few years. Frameworks such as Apache Spark and Apache Storm give developers stream abstractions on which they can develop applications; Apache Beam provides an API abstraction, enabling developers to write code independent of the underlying framework, while tools such as Apache NiFi and StreamSets Data Collector provide a user interface abstraction, allowing data engineers to define data flows from high-level building blocks with little or no coding.
There has been an explosion of innovation in open source stream processing over the past few years. Frameworks such as Apache Spark and Apache Storm give developers stream abstractions on which they can develop applications; Apache Beam provides an API abstraction, enabling developers to write code independent of the underlying framework, while tools such as Apache NiFi and StreamSets Data Collector provide a user interface abstraction, allowing data engineers to define data flows from high-level building blocks with little or no coding.