Getting Started with Cloudera’s Cybersecurity Solution (feat. StreamSets, Arcadia Data and Centrify)
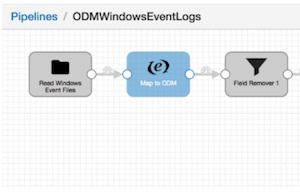 This post was originally published on the Cloudera VISION blog by Sam Heywood. StreamSets configurations and images of Apache Spot Open Data Model ingest pipelines can be found here on Github.
This post was originally published on the Cloudera VISION blog by Sam Heywood. StreamSets configurations and images of Apache Spot Open Data Model ingest pipelines can be found here on Github.
A quick conversation with most Chief Information Security Officers (CISOs) reveals they understand they need to modernize their security architecture and the correct answer is to adopt a machine learning and analytics platform as a fundamental and durable part of their data strategy. However, many CISOs fear deployment of an initial use case will be somewhat daunting. Cloudera has partnered along with Arcadia Data and StreamSets to make it easier than ever for CISOs to take the first step and deploy basic use cases leveraging data sources common to many environments.