*Post Updated December 14, 2023
Analytics efforts are only as good as the data used for the data pipeline. Like all data solutions, your data ingestion framework must utilize a software architecture to inform workflow. One can refer to software architecture as a blueprint that contains information on the tools, components, and technologies and how these building blocks interact to help build your product. The analytics architecture usually begins with data ingestion as its first step. Here, the system ingests data from multiple sources like Customer Relationship Management (CRM), Enterprise Relationship Management (ERM), social media, and software applications for analytics and business decision-making. Depending on your business data goals, budget, and the timeline for products/solutions, your ingestion may follow the real-time, batch, or lambda ingestion architecture.
Defining your ingestion architecture should occur before proceeding with ingestion, as any changes in architectural design or components may mean changes to tooling and timeliness, which translates to more costs. Additionally, your architectural design requires constant communication from stakeholders and engineers to help define your architectural needs and build an ingestion system that fulfills technological and business needs.
Let’s discuss data ingestion architecture and some factors to consider when designing your ingestion framework for your ingestion pipelines.
What is Data Ingestion Architecture?
Data ingestion architecture refers to the systems, processes, and workflows involved in getting data into a database, data warehouse, lakehouse, or other storage repository where it can be analyzed and used.
There are two main types of data ingestion: Batch Processing and Real-Time (or Stream) Processing. These methods differ primarily in how and when they collect and process data:
The Two Main Types of Data Ingestion At-a-Glance
| Batch processing | Real-time Processing | |
| Timing | Data is collected in large ‘batches’ at scheduled intervals — hourly, daily, weekly, etc., depending on the system’s requirements. | Data is ingested and processed continuously in real-time or near real-time. |
| Suitability | Ideal for scenarios where it’s not necessary to have real-time data insights and where processing large volumes of data at once is more efficient. | Best for scenarios where immediate data processing and quick decision-making are crucial. |
| Characteristics | Often simpler and less resource-intensive compared to real-time processing. The downside is latency in data availability and potential relevancy. | More complex and resource-intensive due to the need for constant data processing and immediate response. It often requires more sophisticated technology, like stream processing engines. |
| Use cases | Common in situations where the data doesn’t change rapidly, like processing sales records at the end of the day or generating daily reports. | Typical in scenarios like fraud detection, monitoring of financial transactions, real-time analytics in IoT devices, and live data feeds. |
Choosing between batch and real-time processing depends on the specific needs and constraints of the project, such as the nature of the data, the required speed of insights, resource availability, and the technical infrastructure. Often, organizations use a combination of both to meet different needs within their data strategy.
What Are the Stages of Data Ingestion?
The stages of data ingestion become clear when we look at the components of a typical data ingestion pipeline:
- Data Extraction: This first stage involves extracting the raw data from its source system(s), for example, extracting log files from web servers, getting new transaction records from an OLTP database, or downloading data exports from a SaaS application.
- Data Validation: Once extracted, the raw data should go through basic validation checks for completeness, correctness, and integrity using type checking, range checks, mandatory field checks, etc. This stage helps catch any data quality issues early.
- Data Transformation: Here, the validated raw data gets transformed to prepare it for loading into the target system. Transformations may include filtering, cleansing, joining data from multiple sources, splitting complex records, enforcing uniform schemas, aggregating, encoding values, etc.
- Data Loading: Transformed data gets loaded into the analytics database, data warehouse, data lake, or another persistent store location for reporting, analytics, machine learning, etc. Common loading methods include bulk loads for batch data or real-time, incremental loads via messaging systems.
- Data Quality Monitoring: After loading, statistics on row counts, errors encountered, data completeness, etc., are tracked to monitor quality levels and detect potential issues with the ingestion process.
- Metadata & Catalog Updates: Finally, metadata stores and data catalogs get updated with details about newly available data sets, columns, quality metrics, and other technical metadata to enable discoverability.
The entire pipeline runs on a scheduled basis (daily, hourly, etc.) to keep bringing in the latest source data. Automation and stability of these pipelines are essential to smooth analytics operations.
The Layers of Data Ingestion Architecture
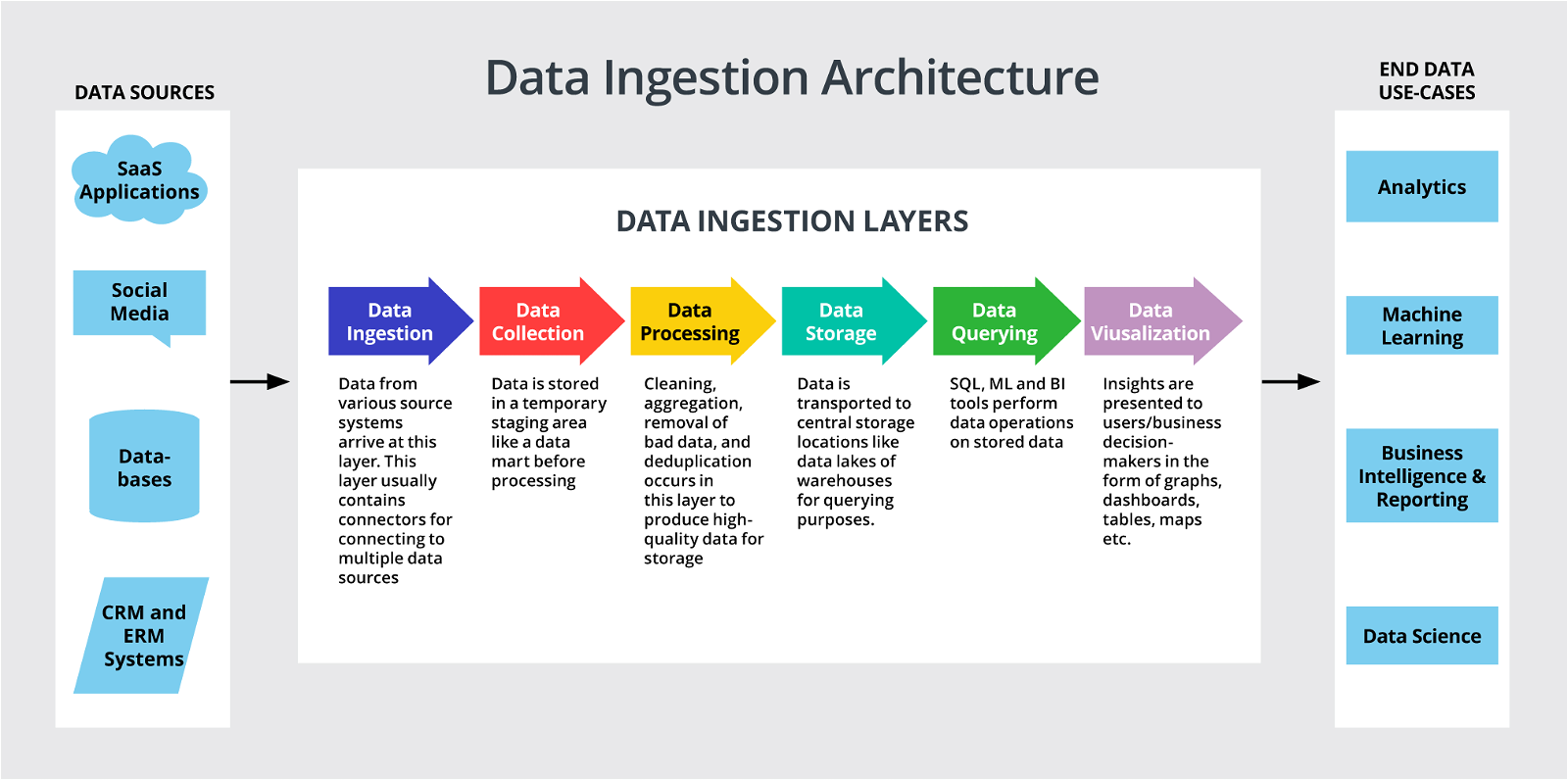
The data ingestion architecture involves six layers, with data ingestion at the top layer bringing data from multiple sources and the visualization layer at the last layer. This ingestion layer makes consistent and high-quality data available for the other layers. Due to the heterogeneity and massive volume of data today, your data ingestion framework must select tools that can automate and adapt to growing data needs. Additionally, any inefficiencies from the ingestion layer affect other downstream processes, hence calling for tools that ensure data quality and security.
Here’s a look at the data ingestion layers present in the data ingestion architecture:
- Data ingestion layer: In this layer, data arrives from sources like social media, CRM and ERM systems, Internet of Things (IoT), and SaaS applications and uses tools like connectors to connect to data sources, validation, and error handling mechanisms. With this layer, data becomes available for the other layers. Data ingestion could be in real-time or in batches, and your choice of ingestion type depends on your business goal, ingestion tools, and budget.
- Data collection layer: The data collection layer contains all the data collected from the ingestion layer and stores it in a temporary staging area for the processing layer.
- Data processing layer: This layer involves data transformation processes that improve data quality. It may include data cleaning, aggregation, and deduplication to produce a high-quality data set.
- Data storage layer: This layer could be a data lake or data warehouse and stores large volumes of the processed data for querying and analytic processes.
- Data query layer: This is the analytical layer and may employ SQL, business intelligence or ML tools to perform analysis and queries on the stored data.
- Data visualization layer: The data visualization layer is the final layer, presenting data insights via visualizations like graphs and dashboards.
Because ingestion represents the entry point for most organizational data, it informs critical data management processes like data integration, security, storage, and governance. For example, it occupies the first step in your data integration architecture, which helps collate data from multiple sources to create a unified view. In addition, most data integration tools like StreamSets offer a platform containing pipelines for seamlessly performing your data ingestion tasks.
Parameters for Designing a Data Ingestion Solution
After choosing what ingestion pipeline architecture to follow, designing your ingestion framework comes next. Your data ingestion framework represents a set of tools and processes for efficiently ingesting data. Your data ingestion framework helps ensure consistency and reliability and reduces the complexity of designing ingestion pipelines. Your ingestion framework pattern must fulfill the following requirements:
- Scalable to handle an organization growing data needs
- Reliable to ensure ingestion proceeds smoothly. Performing checks throughout the pipeline stages helps improve the reliability of your ingestion.
- Efficient to ensure maximum use of time and resources. One way to improve efficiency is by automating repetitive tasks like processing and loading.
- Flexible to handle an organization changing business needs and accommodate the variable data formats present in today’s data landscape.
- Secure to prevent data leaks/loss and comply with data privacy laws and regulations.
Therefore, your ingestion framework must consider data formats, volumes, velocity, frequency of ingestion, and security. For example, a stock-trading application must use tools that enable stream ingestion to fulfill the response timeliness required to provide business value.
Data Velocity
Data velocity refers to the speed with which data enters your system and how fast it takes for processing to occur. It can affect network latency and user traffic. Your design must account for questions like:
- How fast does data flow occur?
- Will this velocity compete with my business traffic? Can my network bandwidth handle the data flow? Will it increase latency for my users?
Data Volume
All data ingestion tools are built in different ways and have workload limits, some to the petabyte or terabyte scale. Therefore, in deciding what ingestion tools to implement, you must ask questions like:
- What is the volume of data ingested frequently? How many rows/columns are present?
- Are there plans to scale in the future? Will our solution scale to accommodate the growing/changing business demand?
Fulfilling this requirement is essential because if your data workload exceeds your ingestion system, it may result in downtimes for your business.
Data Frequency
Your ingestion framework should note your business goal, timeliness of responses, and budget to select the best ingestion design.
- How often does ingestion from sources occur?
- What is the response time needed on the data to create value? Some data contain a time window and lose value for longer response times.
- Will batched or real-time streaming work? Can we implement micro-batching to ensure near real-time updates?
Some tools can only handle batch ingestion, while others, like StreamSets, offer batch plus CDC, real-time, and streaming pipelines. Be sure your chosen ingestion platform supports your ingestion frequency needs to maximize your data value.
Data Format
Your ingestion design must consider data schema and format in your workflow.
- In what format does the data arrive? Is it unstructured, like video or text, or structured, like JSON and CSV?
- Does this tool validate and enforce schema? Can we afford the engineering time needed to configure and validate the schema if not?
Some tools require engineering teams to set up and configure your schema before ingestion; others, like StreamSets, save you engineering time and effort by operating on schema on read (i.e., you don’t have to define a schema before ingestion).
Monitoring and Tracking
Most organizations will have numerous data sources and must prioritize the sources to include in their ingestion pipeline to avoid having bad and unnecessary data. Additionally, your tooling infrastructure must employ ingestion best practices like validating data at strategic points in the pipeline, auditing, log-viewing, and visualizations to observe and track the ingestion workflow.
Data Security and Governance
Ensuring data security and governance is crucial to your ingestion design and may involve asking questions like:
- Who has access to this data?
- Will data be consumed internally or externally?
- Are sensitive data like Personally Identifiable Information (PII) present in the data?
- What are some security measures to implement to ensure no leaks or breaches?
Every ingestion tool combines data security and privacy methods to ensure governance during ingestion. These methods include encryption, security protocols like SSHH, HTTPS, SSL/TLS, and IPSec, data quality checks, and data audits. Implementing one or more of these measures depends on your organization’s needs and objectives. For example, for healthcare and finance industries with strict data privacy regulation laws, your ingestion pipeline should include security measures to hide PII to prevent sensitive data leaks.
Streamlining Data Ingestion
Data ingestion represents the first layer for analytics and thereby affects other downstream layers. Hence, it requires an ingestion workflow to inform the process. Your ingestion design should consider data volume, format, frequency, and security/protection to build an effective, reliable, scalable ingestion pipeline. StreamSets lets your organization implement streaming and batch ingestion pipelines on its platform. Its simplified and user-friendly GUI offers multiple connectors for easy connection to your data sources and reusable pipelines to construct robust ingestion pipelines. Organizations with custom data needs can also utilize the custom scripting option to make advanced configurations to their pipelines.
The StreamSets Control Hub also offers extensive pipeline monitoring allowing you to track and monitor your ingestion workflow and view pipeline error information for troubleshooting.
