Calling External Java Code from Script Evaluators
![]() When you’re building a pipeline with StreamSets Data Collector (SDC), you can often implement the data transformations you require using a combination of ‘off-the-shelf’ processors. Sometimes, though, you need to write some code. The script evaluators included with SDC allow you to manipulate records in Groovy, JavaScript and Jython (an implementation of Python integrated with the Java platform). You can usually achieve your goal using built-in scripting functions, as in the credit card issuing network computation shown in the SDC tutorial, but, again, sometimes you need to go a little further. For example, a member of the StreamSets community Slack channel recently asked about computing SHA-3 digests in JavaScript. In this blog entry I’ll show you how to do just this from Groovy, JavaScript and Jython.
When you’re building a pipeline with StreamSets Data Collector (SDC), you can often implement the data transformations you require using a combination of ‘off-the-shelf’ processors. Sometimes, though, you need to write some code. The script evaluators included with SDC allow you to manipulate records in Groovy, JavaScript and Jython (an implementation of Python integrated with the Java platform). You can usually achieve your goal using built-in scripting functions, as in the credit card issuing network computation shown in the SDC tutorial, but, again, sometimes you need to go a little further. For example, a member of the StreamSets community Slack channel recently asked about computing SHA-3 digests in JavaScript. In this blog entry I’ll show you how to do just this from Groovy, JavaScript and Jython.
 I’m frequently asked, ‘How does
I’m frequently asked, ‘How does 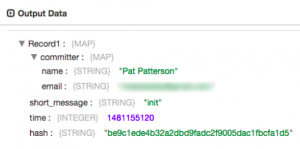 Since writing tutorials for creating
Since writing tutorials for creating  As you likely already know,
As you likely already know,