UPDATE – Salesforce origin and destination stages, as well as a destination for Salesforce Wave Analytics, were released in StreamSets Data Collector 2.2.0.0. Use the supported, shipping Salesforce stages rather than the unsupported code mentioned below!
After I published a proof-of-concept Salesforce Origin for StreamSets Data Collector (SDC), I noticed an article on the Elastic blog, Analyzing Salesforce Data with Logstash, Elasticsearch, and Kibana. In the blog entry, Elastic systems architect Russ Savage (now at Cask Data), explains the motivation for ingesting Salesforce data into Elasticsearch:
Working directly with sales and marketing operations, we outlined a number of challenges they had that might be solved with this solution. Those included:
- Interactive time-series snapshot analysis across a number of dimensions. By sales rep, by region, by campaign and more.
- Which sales reps moved the most pipeline the day before the end of month/quarter? What was the progression of Stage 1 opportunities over time.
- Correlating data outside of Salesforce (like web traffic) to pipeline building and demand. By region/country/state/city and associated pipeline.
It’s very challenging to look back in time and see trends in the data. Many companies have configured Salesforce to save reporting snapshots, but if you’re like me, you want to see the data behind the aggregate report. I want the ability to drill down to any level of detail, for any timeframe, and find any metric. We found that Salesforce snapshots just aren’t flexible enough for that.
Since we have first-class support for Elasticsearch as a destination in SDC, I decided to recreate the use case with the Salesforce Origin and see if we could fulfill those same requirements while taking advantage of StreamSets’ interactive pipeline IDE and ability to continuously monitor origins for new data.
 Riak KV is an open source, distributed, NoSQL key-value data store oriented towards high availability, fault tolerance and scalability. With its initial release in 2009, Risk KV is in use at companies such as AT&T, Comcast and GitHub. Last October, Basho, the vendor behind Riak KV, announced Riak TS. Riak TS, another distributed, NoSQL data store, is optimized for time series data generated by sources such as IoT sensors. The recent release of Riak TS 1.3 as an open source product under the Apache V2 license got me thinking – how would I get sensor data into Riak TS? There are a range of client libraries, which communicate with the data store via protocol buffers, but connected devices tend to use protocols such as MQTT, an extremely lightweight publish/subscribe messaging transport. StreamSets to the rescue!
Riak KV is an open source, distributed, NoSQL key-value data store oriented towards high availability, fault tolerance and scalability. With its initial release in 2009, Risk KV is in use at companies such as AT&T, Comcast and GitHub. Last October, Basho, the vendor behind Riak KV, announced Riak TS. Riak TS, another distributed, NoSQL data store, is optimized for time series data generated by sources such as IoT sensors. The recent release of Riak TS 1.3 as an open source product under the Apache V2 license got me thinking – how would I get sensor data into Riak TS? There are a range of client libraries, which communicate with the data store via protocol buffers, but connected devices tend to use protocols such as MQTT, an extremely lightweight publish/subscribe messaging transport. StreamSets to the rescue! A couple of weeks ago, as May the 4th approached, a lively Star Wars debate brewed at StreamSets:
A couple of weeks ago, as May the 4th approached, a lively Star Wars debate brewed at StreamSets: UPDATE – Salesforce origin and destination stages, as well as a destination for Salesforce Wave Analytics, were released in StreamSets Data Collector 2.2.0.0. Use the supported, shipping Salesforce stages rather than the unsupported code mentioned below!
UPDATE – Salesforce origin and destination stages, as well as a destination for Salesforce Wave Analytics, were released in StreamSets Data Collector 2.2.0.0. Use the supported, shipping Salesforce stages rather than the unsupported code mentioned below!
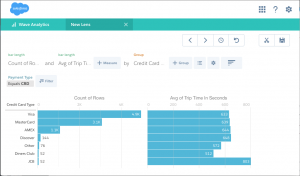 UPDATE – Salesforce origin and destination stages, as well as a destination for Salesforce Wave Analytics, were
UPDATE – Salesforce origin and destination stages, as well as a destination for Salesforce Wave Analytics, were