 June 2018 marked the fourth anniversary of StreamSets’ founding; here’s a look back at the past four years of StreamSets and the Data Collector product, from the early days in stealth-startup mode, to the recent release of StreamSets Data Collector 3.4.0.
June 2018 marked the fourth anniversary of StreamSets’ founding; here’s a look back at the past four years of StreamSets and the Data Collector product, from the early days in stealth-startup mode, to the recent release of StreamSets Data Collector 3.4.0.
Girish Pancha and Arvind Prabhakar founded StreamSets on June 27th, 2014. Girish had been at Informatica for many years, rising to the level of Chief Product Officer; Arvind had held technical roles at both Informatica and Cloudera. Between them, they had realized that the needs of enterprises were not being met by existing data integration products – for instance, the best practice for many customers ingesting data into Hadoop was laborious manual coding of data processing logic and orchestration using low-level frameworks like Apache Sqoop. They also realized that this would be true for other proliferating data platforms such as Kafka (Kafka Connect), Elastic (Logstash) and cloud infrastructure (Amazon Glue, etc.). The main obstacle they identified was ‘data drift’, the inescapable evolution of data structure, semantics and infrastructure, making data integration difficult and solutions brittle. Data drift exists in the traditional data integration world, but grows and accelerates when dealing with modern data sources and platforms. The founding vision for StreamSets was to ”solve the data drift problem for all modern data architectures”.

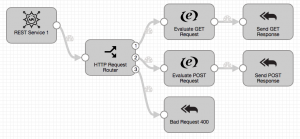 A microservice data pipeline is a lightweight component that implements a relatively small component of a larger system – for example, providing access to user data. A microservice architecture comprises a set of independent microservices, often implemented as RESTful web services communicating via JSON over HTTP, that together implement a system’s functionality, rather than a single monolithic application. Think of an e-commerce web site: we might have separate microservices for searching for inventory, managing the shopping cart, and recommending items based on the shopping cart’s content. Compared to monolithic applications, the microservice approach promotes fine-grained modularity, allowing agile implementation of components by independent teams, which may even be using different technologies. Now, one of those technologies can be
A microservice data pipeline is a lightweight component that implements a relatively small component of a larger system – for example, providing access to user data. A microservice architecture comprises a set of independent microservices, often implemented as RESTful web services communicating via JSON over HTTP, that together implement a system’s functionality, rather than a single monolithic application. Think of an e-commerce web site: we might have separate microservices for searching for inventory, managing the shopping cart, and recommending items based on the shopping cart’s content. Compared to monolithic applications, the microservice approach promotes fine-grained modularity, allowing agile implementation of components by independent teams, which may even be using different technologies. Now, one of those technologies can be