 The term DataOps is a contraction of ‘Data Operations’ and comes from applying DevOps to data. It seems to have been coined in a 2015 blog post by Tamr co-founder and CEO Andy Palmer. In this blog post, I’ll dive into what DataOps means today, and how enterprises can adopt its practice to create reliable, always-on dataflows using smart data pipelines to unlock the value of their data.
The term DataOps is a contraction of ‘Data Operations’ and comes from applying DevOps to data. It seems to have been coined in a 2015 blog post by Tamr co-founder and CEO Andy Palmer. In this blog post, I’ll dive into what DataOps means today, and how enterprises can adopt its practice to create reliable, always-on dataflows using smart data pipelines to unlock the value of their data.
In his 2015 post, Palmer argued that the democratization of analytics and the implementation of “built-for-purpose” database engines created the need for DataOps. In addition to the two dynamics Palmer identified, a third has emerged: the need for analysis at the “speed of need”, which, depending on the use, can be real-time, near-real-time or with some acceptable latency. Data must be made available broadly, via a more diverse set of data stores and analytic methods, and as quickly as required by the consuming user or application.
What’s driving these three dynamics is the strategic imperative that enterprises wield their data as a competitive weapon by making it available and consumable across numerous points of use, in short, that their data enables pervasive intelligence. The centralized discipline of SQL-driven business intelligence has been subsumed into a decentralized world of advanced analytics and machine learning. Pervasive intelligence lets “a thousand flowers bloom” in order to maximize business benefits from a company’s data, whether it be speeding product innovation, lowering costs through operational excellence or reducing corporate risk.
Data Drift – a Modern Disease that Requires New Medicine
In the same way that diabetes is a disease that has come to the fore due to living in a land of plenty, there is an ailment that infects data delivery that has arisen due to the sheer complexity of the emerging data ecosystem – data drift. Data drift is the unending, unexpected and unpredictable changes to data structure and semantics. Data drift can break data pipelines and bring data-driven applications to a halt, or even worse, insidiously invalidate analysis by polluting the data.
Data drift is caused by the explosion of complexity in the data supply chain. It is a consequence of unexpected changes to data sources, especially external data feeds or loosely governed sources such as systems logs. It is induced by changes to the infrastructure processing the data, such as a move to the cloud. Lastly, data drift is caused by changing business requirements, for instance the addition of latitude and longitude to an address table. Data drift happens without notice, and the consequences impact data stores and downstream applications and consumers.
Legacy data integration assumed a privileged cadre of analysts, and a single analytical ‘source of truth’ with a tightly controlled relational schema. Data integration was analogous to the traditional ‘waterfall’ approach to software engineering – taking an inventory of operational systems, building the all-encompassing data warehouse, and then bask in the glow of its perfection. The more audacious requirements of pervasive intelligence combined with the peril of data drift break this traditional approach to data movement. The proper response a new, agile “DataOps” discipline to deal with this more fluid environment.
The Agile Manifesto and DevOps
In 2001, a group of software developers established the Agile Manifesto, a declaration of the tenets of Agile Software Development:
We are uncovering better ways of developing software by doing it and helping others do it.
Through this work we have come to value:
Individuals and interactions over processes and tools
Working software over comprehensive documentation
Customer collaboration over contract negotiation
Responding to change over following a plan
That is, while there is value in the items on the right, we value the items on the left more.
The traditional waterfall model of software development had a team of systems analysts producing a requirements document, from which a team of software architects produced a system architecture, from which a team of developers wrote the application, which a QA team would then test. Each step could take weeks, months or even years, with no working software available until the conclusion of system testing. If the process did result in a working application, it was more often than not late, or even obsolete before it went live.
The agile approach, in contrast, encourages multidisciplinary teams focused on an iterative development model. An agile team comprises analysts, designers, developers, QA engineers and even users, working in close proximity. The agile team starts by building a minimal working application, delivering it to users as soon as possible so that the next iteration can take their feedback into account.
On its own, agility brings benefits to software engineering. The focus on building working systems with an iterative approach delivers real business value – but a functional system is not the end point. DevOps, and DataOps in turn, looks beyond system delivery to operations.
Development + Operations = DevOps
DevOps brings operations staff into the development loop, broadening the scope of the agile approach from delivering applications to their entire operational lifetime. Developers take into account operational needs by designing applications for easy automation, scaling and high availability. From its origins in Internet giants such as Amazon, Facebook and Netflix, DevOps is now becoming standard practice across the industry.
Applying DevOps to Data + Operations = DataOps
If we substitute ‘delivering data’ in place of ‘developing software’ in the Agile Manifesto, we can apply it to the world of data engineering. In the world of data engineering, the term DataOps to describe a multidisciplinary approach to delivering value through data in the enterprise.
Just as DevOps brought users, developers, QA and operations staff together to tackle the problems of software delivery, DataOps brings data practitioners together to continuously deliver quality data to applications and business processes. End-users of data, such as data analysts and data scientists, work closely with both data engineers and IT Ops to deliver continuous data pipelines that link many sources to many destinations while dealing with the reality of data drift. It achieves a combination of robustness and flexibility by using an iterative approach to design and operate data movement logic from source to store to analysis.
We think of DataOps as supporting an iterative lifecycle for data pipelines including build, execute and operate steps supported by data protection:
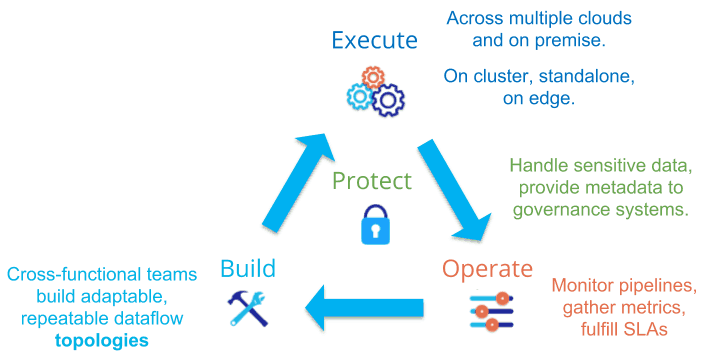
- Build – design topologies of flexible, repeatable dataflow pipelines using configurable tools rather than brittle hand-coding.
- Execute – run pipelines on edge systems and in auto-scaling on-premise clusters or cloud environments.
- Operate – manage dataflow performance through continuous monitoring and enforcement of Data SLAs to tie development goals to operational reality.
Just as DevOps treats application security as an overarching concern, to be considered at every point in the process, in DataOps we must protect data at every point of its journey, both from the bad guys as well as inadvertent sharing of sensitive data that is subject to regulatory compliance.
Let’s look at each aspect in turn:
Building Data Pipelines
Part of any DataOps team’s responsibilities is the construction of a collection, or topology of dataflow pipelines. A dataflow pipeline consumes data from a point of origin, which might be a relational database, log file, message queue or any other data source. The pipeline might apply one or more transformations, enriching or filtering the data, before writing it to some set of destinations – typically an analytical data store or a message queue. In the spirit of agile methodology, the scope of any given pipeline is deliberately narrow – read data from one origin, optionally apply transformations, and write the results to one or more destinations. DataOps teams are able to realize value quickly, in small increments, rather than trying to ‘boil the ocean’.
To accomplish anything of value, many dataflow pipelines need to connect to one another, either directly feeding data from one to the other, or indirectly via message queues or data stores. As the DataOps team builds out its collection of pipelines, it’s natural to organize them into topologies that constitute the core unit of operational management. A topology allows the DataOps team to trace the path of data from its point of origin, through multiple pipelines, to its ultimate destination. This enterprise view provides end-to-end visibility and crucial insights when pipelines are operational.
DataOps emphasizes configuration over code, minimizing time to delivery and maximizing reuse. DataOps tools allow non-developers to build data pipelines, sharing them between team members to allow iterative development. Pipelines are stored using open formats, allowing easy automation and eliminating duplication of effort.
The DataOps team and tools it uses should anticipate data drift. In some circumstances, such as feeds from an operational database, data drift is an anomaly, and any unforeseen change in data structure must be flagged for attention. In others, such as when using external or semi-structured data, data drift is expected as upstream data sources change unexpectedly. In the later case it is ideal if pipelines automatically propagate changing schemas to their destinations.
Executing Data Pipelines
As the DataOps team puts its pipelines into production, it must consider the environment in which they can most effectively run. Does it make sense for a pipeline to execute on a cluster, or at the edge, on premises or on public cloud infrastructure?
Often the enterprise has an existing investment in a cluster technology and is looking to maximize return on its investment there, so it’s important that pipelines can run natively on the existing cluster.
Are one or more cloud-based data stores in play? The DataOps team must take care to select data movement tools that are not tied to a single data store vendor; such tools are “free like a puppy”. They can certainly ease the task of writing data to that vendor’s data store, but create lock-in that can get very expensive by making it difficult to move data out to another destination.
DataOps tools give the team flexibility to start small, and then scale up and out once the data pipeline topology is proven with managed data pipelines. The most flexible tools can scale from exploration and proof-of-concept on a single laptop to clustered deployments able to handle millions of records per second.
Operating Data Pipelines
If we were simply applying agile software development principles to data engineering, we would be done at this point, but the “go live” event for a topology of pipelines is far from the end of the DataOps story, it is really the beginning. Once the system is deployed, data pipelines must be monitored, throughput measured and latency compared to service level agreements. Ideally the data values themselves are sampled to efficiently detect data drift.
Automated monitoring of data pipelines allows the DataOps team and tools to rapidly react to changing conditions, scaling up pipelines to handle seasonal or unexpected demand. Here the iterative aspects of the agile approach come into play. One agile principle, ‘You aren’t going to need it’, or YAGNI for short, advocates against building complexity into a system before it’s required. The DataOps team starts small, building data pipelines to prove out the approach and satisfy initial demand, then cycling back to the build activity as operational experience reveals new requirements.
Protecting Data Pipelines
Data protection is paramount throughout the DataOps cycle. At a minimum, DataOps tools must integrate with data stores’ authentication and authorization systems, and protect data from unauthorized access and modification when it is in transit, but data protection goes much further than this.
Under current and impending data regulations, the costs of mishandling personally identifiable data are becoming prohibitive. So a DataOps effort must employ techniques that can detect sensitive data in-flight, and automatically remove, mask or otherwise redact the data before it is written to any analytical data stores. For example, an operational system might quite legitimately store customer phone numbers for day-to-day business purposes, but in order to comply with regulations such as GDPR, this personally identifiable information (PII) might be better off masked in-flight before being presented to any analytical systems.
Much innovation is happening in this area, with new tools helping to automate the process of detecting and redacting PII within the data pipeline. The application of machine learning to data protection promises to further ease the DataOps team’s burden.
From DevOps to DataOps – an Evolving Discipline
Compared to DevOps, which is now more than a decade old, DataOps is in its infancy. Still, DataOps is gaining steam; As a milestone for notoriety, research firm Gartner recently published their annual Hype Cycle for Data Management and DataOps was included for the first time. Veteran Gartner research VP Nick Heudecker penned a supporting post on Gartner’s public blog which provides a useful summary of Gartner’s current point of view.
StreamSets is building the tools that enable enterprises to adopt a DataOps approach and deliver value through data at unprecedented scale. Our DataOps platform provides the tools that teams can use to build, execute, operate and protect data pipeline topologies at scale and in the face of data drift.
StreamSets hosted the first DataOps Summit in 2019. To hear from technical and business practitioners about their DataOps practice, check out these DataOps Case Studies.
Contact StreamSets today for more information, or to arrange a demonstration of the StreamSets DataOps Platform.